I can't believe your video views bcz your explaination is on next level dude i thought it must have crossed atleast 1lakh but i hope it will soon cross it
I just started to realize the potential of AI, I already feel behind with all these new tools. Would love to see another video in the future about BlueWillow that is completely free
When I run the code on streamlit it shows two errors: 1. ValueError: axes don't match array. 2. ValueError: The name "conv2d" is used 2 times in the model. All layer names should be unique. How can I solve the problem?
Hey, great lecture! Just need a help, the link for the google colab for image captioning with rnn isn't working. It would be great help if you'll provide a new link. Thankyou!!
Bro, let me give you a salute that in this age you are doing a incredible job. BTW lets came into the main purpose..as i am in your comment section you must have guesed that I am having trouble in understanding the attention mechanism and tensorflow overall. I have to submit my paper in next one month and I am having many problems it would be great if you work with me in speech domain.please response fast.
It’s a good tutorial. But I have a question regarding attention mechanism. At 4:50, how doest it know to focus on dog getting "dog" words as input? If it knows by detecting object, then how does it know to focus on somewhere else when it receives "It/The/There/Eating/Water/Flying"? Please make it clear.
hey i looked into your kaggle notebook of transformer model with coco dataset, you mentioned that you only trained the model on 14k images for coco dataset , im a beginner in ml ,so can you tell me what should i change in your code to increase the training dataset size from 14k
I tried to use your project but when I tried to run it, it shows this error -> File "h5py\_objects.pyx", line 54, in h5py._objects.with_phil.wrapper File "h5py\_objects.pyx", line 55, in h5py._objects.with_phil.wrapper File "h5py\h5f.pyx", line 106, in h5py.h5f.open OSError: Unable to open file (file signature not found) Can you please help me solve this error and also can you please share the link to model.h5 file
Hi,when i try to run it on streamlit it displays the error "ImportError: cannot import name 'get_caption_model' from 'model' (C:\Users\z\model.py)",what am i doing wrong? Sorry i'm totally new to this,so can you pls help (i also downloaded both the H5 files too)
Have you downloaded the model.py file? If not, You can download it here: github.com/pritishmishra703/Image-Captioning/blob/master/model.py The 'get_caption_model' function is present in this file.
@@PritishMishra I want to use the model that you have deployed on HuggingFace. Is it possible? Or if possible, can you pls share with me your trained model?
Yes, you can do this just by using batching. See HuggingFace documentation for more info, it's easy to do. Post any errors/issues here if you encounter any.
i want to do the image captioning with unsupervised or semi supervised bro if you have any reference code or implemented code if you share it will be helpful to me
Thanks for replying! I Am excited to see that we can use modal.h5 file and directly build project without training it.Wouldn't it be nice if someone managed to get coco trained full dataset modal.h5 file ...
Hey can you please give the code that you wrote in streamllit? And also, how's the huge COCO data set is processing on localhost?? And then how did you hosted that on huggingface? Also which one is hosted on higging face? RNN one or Transformer one or COCO dataset one?Please tell me how do I run it on localhost without downloading the whole dataset on my machine.
the code that I wrote in streamllit: huggingface.co/spaces/pritish/BookGPT/tree/main how's the huge COCO data set is processing on localhost? Answer: I trained my model on COCO dataset, I loaded the dataset once on Google Colab. Once the training was done, I saved the trained model weights to a file. Now, when I want to use the trained model for inference or fine-tuning (on my localhost), I only need to load the saved model from the file, not the entire COCO dataset. How did you hosted that on huggingface? Answer: I created an app.py file that includes a user interface (UI) made with Streamlit. Then I pushed it to huggingface spaces. Here's how to do it: huggingface.co/docs/hub/spaces-overview#creating-a-new-space which one is hosted on higging face? RNN one or Transformer one or COCO dataset one? Answer: The Transformer + COCO one is hosted on HuggingFace. Please tell me how do I run it on localhost without downloading the whole dataset on my machine. Answer: As I said, there's no need to download the whole dataset. You just need to load the model file ('model.h5') and then you can give it any image and it will generate captions. First clone the repository: git clone huggingface.co/spaces/pritish/BookGPT Then run the `app.py` file. This will take some time as it imports all the modules and loads the saved model. This will raise error if you don't have TensorFlow installed so make sure it is installed!
Kind of a dumb question, Why do we train the dataset again if we are already using a pre trained coco dataset cnn model to extract the features as the encoder. Still new to this area.
The Inception V3 is trained for image classification (cloud.google.com/tpu/docs/inception-v3-advanced#introduction ) so we are *fine-tuning* it on our caption generation task. In simple words: The InceptionV3 is NOT specialized for doing Image captioning so fine-tuning can help the model learn task-specific features.
@@PritishMishra Thanks, i been training this for 10 epochs but it stops 8 epochs and results are not much accurate, btw is it possible to retrain the model with saved weights? i have weights that run over 8 epochs with loss: 2.6367 - acc: 0.4514 , please reply ASAP
Accuracy 0.45 is great i would say! If you want to increase it more I recommend you to train it on more data (i have trained on 14K images, make it 24K or 30K). If you load my save weights you will save some epochs of training.
how to use model.h5 file to make predictions ???? , I tried using load_model but it's expecting checkpoints file, also tried load_weights but still giving error can u pls show how to use this model.h5 file to make predictions ??????????
You can use `get_caption_model` function to load the model: github.com/pritishmishra703/Image-Captioning/blob/master/model.py#L299 Then to make predictions use `generate_caption` function: github.com/pritishmishra703/Image-Captioning/blob/master/model.py#L270
hi can you help me please,, when i call get_caption_model() function i get the following error "ValueError: axes don't match array" do you you have any ideas
Hi, I tried testing your model and it was not giving correct captions most of the time like whenever I uploaded a simple face image, it would always prompt "a man in a suit and tie". I am new to ML/DL and wanted to make my first project on this topic. How can I make it prompt more accurate with diverse captions?
I haven't tried training it on whole dataset but i am sure that the caption accuracy will increase if you do it. Make sure the model doesn't overfit. This may increase the generalization capabilities of the model.
@@PritishMishra Okay I'll give that a try. In project building, Should I opt for a pre-trained model like ViT model from hugging face and use Pytorch for processing. The whole project is completed within 30 lines of code and the accuracy is extremely high as well. Do let me know your thoughts on that.
@@blackplagueklan7246 can you share the notebook with me? I want to see the performance. I will be glad to share the link with everyone in description!
The Image Captioning model is a generative model, which means that it predicts a new caption for each image. You may be aware that the predictions are generated word by word; the model generates new words depending on the words it predicted previously, and generative models are highly chaotic; a minor change in their initial conditions can completely affect the structure of the predicted captions. That's why, accuracy is a hard metric to use when evaluating such models because even a single extra word in the model's prediction might entirely ruin the accuracy. In short, 43% is moderately good accuracy for our model.
Brother this video is really great and i loved your explanation but i am a beginner in aiml and want to learn this in detail Can you please create a detail video on this topic
"with open(f'{BASE_PATH}/annotations/captions_train2017.json', 'r') as f:" what is this path in the code???? i can not get it and it is showing me directory error pllzzz reply me i m stuck since long!! i m geeting directorary error in each code
Hello, I originally made that notebook on Kaggle. So I forgot to include that downloading code on colab. I'm doing it right now. However, I strongly advise you to run that file on Kaggle because the coco dataset is 27 GB and downloading it on colab will take forever. So, to execute the file on Kaggle, do the following: 1. Download the notebook from colab. (Go to File -> Download -> Download .ipynb) 2. Go to Kaggle and sign in. 3. Then, on the left menu, click the big "+" button. 4. Select "Create Notebook." 5. You should now be able to see the newly created notebook. Now, Go to File -> Import Notebook 6. Upload the file you downloaded in Step 1. 7. You should now be able to see the entire notebook. Now, on the right pane, click the "Add Data" button. 8. Look for Awsaf's "Coco 2017 Dataset" and add that dataset. (This one: bit.ly/3Vcst64) You're good to go! Run the notebook now, and everything should be fine. If you encounter any new errors, please reply here and I will help you.



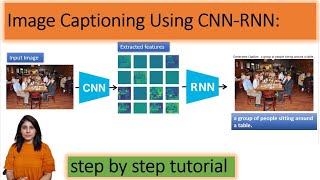






Here's how I created a search engine for books using GPT3: ruclips.net/video/SXFP4nHAWN8/видео.html
I can't believe your video views bcz your explaination is on next level dude i thought it must have crossed atleast 1lakh but i hope it will soon cross it
Thanks!
Awesome video 🔥 and nice animation as always (or not it was more dramatic 😂😂😂) Way to go 👍🏻👍🏻👍🏻
Yeah, I overdid the Transformer Introduction XD.
Awesome Video bro !! You explained Image captioning in a simple and fun way.
Amazing video! You made it interesting and practical. The memes and effects were lit.
I just started to realize the potential of AI, I already feel behind with all these new tools. Would love to see another video in the future about BlueWillow that is completely free
it's not a tutorial it's a movie i really enjoy it💙
How to use the saved model weights model.h5 in another file to make inferences on new images
Just amazing! Loved this video. Keep more coming!
learned so many new things. thanks for making the video.
When I run the code on streamlit it shows two errors:
1. ValueError: axes don't match array.
2. ValueError: The name "conv2d" is used 2 times in the model. All layer names should be unique.
How can I solve the problem?
i had the same problem too
Hey, great lecture! Just need a help, the link for the google colab for image captioning with rnn isn't working. It would be great help if you'll provide a new link. Thankyou!!
How can I save the model and run for android studio?
Bro, let me give you a salute that in this age you are doing a incredible job. BTW lets came into the main purpose..as i am in your comment section you must have guesed that I am having trouble in understanding the attention mechanism and tensorflow overall. I have to submit my paper in next one month and I am having many problems it would be great if you work with me in speech domain.please response fast.
Bro unable to get , Image caption using RNN. The link is not working. Can you please check.
It’s a good tutorial. But I have a question regarding attention mechanism. At 4:50, how doest it know to focus on dog getting "dog" words as input? If it knows by detecting object, then how does it know to focus on somewhere else when it receives "It/The/There/Eating/Water/Flying"? Please make it clear.
Amazing video, where did you learn all of this? omg just saved me so much time. Life safer
hey i looked into your kaggle notebook of transformer model with coco dataset, you mentioned that you only trained the model on 14k images for coco dataset , im a beginner in ml ,so can you tell me what should i change in your code to increase the training dataset size from 14k
Hello there I'm having same problem understanding this can you tell if you found solution? Thank you
Wow,very nicely explained!!!
Nice video. How long does it take you to train the transformer model?
Very nice explanation
I tried to use your project but when I tried to run it, it shows this error ->
File "h5py\_objects.pyx", line 54, in h5py._objects.with_phil.wrapper
File "h5py\_objects.pyx", line 55, in h5py._objects.with_phil.wrapper
File "h5py\h5f.pyx", line 106, in h5py.h5f.open
OSError: Unable to open file (file signature not found)
Can you please help me solve this error
and also can you please share the link to model.h5 file
Same, I m thinking to take it as my major project
you nailed it bro
Link of Images Captioning with RNN was dead, Can you update it to help me. Thank you. From VietNam with love
Github link is not opening , it's says that it was uploaded from a suspended account
Your RNN file is showing Page Not Found , can you reupload the file
link isn't working for "Image Captioning with RNN". @PritishMishra can you please share the code
Hi,when i try to run it on streamlit it displays the error "ImportError: cannot import name 'get_caption_model' from 'model' (C:\Users\z\model.py)",what am i doing wrong? Sorry i'm totally new to this,so can you pls help (i also downloaded both the H5 files too)
Have you downloaded the model.py file?
If not, You can download it here: github.com/pritishmishra703/Image-Captioning/blob/master/model.py
The 'get_caption_model' function is present in this file.
Hi Pritish, Is it possible to use your model's results using web API calls?
Yes, but you will need to deploy it. As per my knowledge, HuggingFace has such features.
@@PritishMishra I want to use the model that you have deployed on HuggingFace. Is it possible? Or if possible, can you pls share with me your trained model?
Image captioning with RNN source code is not opening dude please upload 😊.
Re-upload
If the image already contains 5 captions, then whats the use of generating caption for image. We can use those available captions right?
Hello there. Very helpful im so thankful. can you please provide me with the code to evaluate the model(not just one image) using blue metric
Hey bro! Thanks for the video. Learnt a lot. Your RNN colab links seems to be broken. Can you please update? Thanks!
Awsome video, is it possible to add multiple image upload and generate a caption on each images?
Yes, you can do this just by using batching. See HuggingFace documentation for more info, it's easy to do. Post any errors/issues here if you encounter any.
i want to do the image captioning with unsupervised or semi supervised bro if you have any reference code or implemented code if you share
it will be helpful to me
great! learned a lot.
This is dope brotha!!
hey! It took a lot of time to process fliker 30 k file for so many epochs.
How did you managed to get Coco h5 file??How much time it took to process.
I only trained on random 14K images from coco dataset. So the training time was slightly greater for coco dataset compared to Flickr8K.
Thanks for replying!
I Am excited to see that we can use modal.h5 file and directly build project without training it.Wouldn't it be nice if someone managed to get coco trained full dataset modal.h5 file ...
I am facing a lot of errors, kindly help me out
sir why i can't open the file that consist of image captioning with RNN model
The RNN source code link is not working please provide a link
bro can you help me in Video captioning project?
Can you share the link for pretraiend model ( h5 ) .please share it
Good video editing skills
Hey can you please give the code that you wrote in streamllit? And also, how's the huge COCO data set is processing on localhost?? And then how did you hosted that on huggingface? Also which one is hosted on higging face? RNN one or Transformer one or COCO dataset one?Please tell me how do I run it on localhost without downloading the whole dataset on my machine.
the code that I wrote in streamllit:
huggingface.co/spaces/pritish/BookGPT/tree/main
how's the huge COCO data set is processing on localhost?
Answer: I trained my model on COCO dataset, I loaded the dataset once on Google Colab. Once the training was done, I saved the trained model weights to a file. Now, when I want to use the trained model for inference or fine-tuning (on my localhost), I only need to load the saved model from the file, not the entire COCO dataset.
How did you hosted that on huggingface?
Answer: I created an app.py file that includes a user interface (UI) made with Streamlit. Then I pushed it to huggingface spaces. Here's how to do it: huggingface.co/docs/hub/spaces-overview#creating-a-new-space
which one is hosted on higging face? RNN one or Transformer one or COCO dataset one?
Answer: The Transformer + COCO one is hosted on HuggingFace.
Please tell me how do I run it on localhost without downloading the whole dataset on my machine.
Answer: As I said, there's no need to download the whole dataset. You just need to load the model file ('model.h5') and then you can give it any image and it will generate captions.
First clone the repository:
git clone huggingface.co/spaces/pritish/BookGPT
Then run the `app.py` file. This will take some time as it imports all the modules and loads the saved model. This will raise error if you don't have TensorFlow installed so make sure it is installed!
ur github link is saying that it is suspended
I have a problem in caption key and image signature can pls help me in it
Kind of a dumb question,
Why do we train the dataset again if we are already using a pre trained coco dataset cnn model to extract the features as the encoder. Still new to this area.
The Inception V3 is trained for image classification (cloud.google.com/tpu/docs/inception-v3-advanced#introduction ) so we are *fine-tuning* it on our caption generation task.
In simple words: The InceptionV3 is NOT specialized for doing Image captioning so fine-tuning can help the model learn task-specific features.
hey none of your links are working
It is showing connecting to runtime to enable File browsing after uploading images
How can we do it for videos bro ??
How to get the code
bro unable to get the dataset brooo
Can you tell me how u trained for mscoco dataset for the same, how many epochs did you run to get the results in your video. waiting for your reply
I have added the Jupyter notebook of the entire training on MS COCO. You can find it in description.
@@PritishMishra i couldnt find it,in source code only flickr dataset is used, can u please help me out
The link I provided in the description was wrong 😅 Sorry for that!
Here you go: www.kaggle.com/code/pritishmishra/image-captioning-on-coco-dataset
@@PritishMishra Thanks, i been training this for 10 epochs but it stops 8 epochs and results are not much accurate, btw is it possible to retrain the model with saved weights? i have weights that run over 8 epochs with loss: 2.6367 - acc: 0.4514 , please reply ASAP
Accuracy 0.45 is great i would say! If you want to increase it more I recommend you to train it on more data (i have trained on 14K images, make it 24K or 30K). If you load my save weights you will save some epochs of training.
what is the software at the end of the taskbar called? Just Curious
The one with a red dot? It's obs studio, the screen recording software I am using.
Where is the code of this video
Bro where can i get the full code
Bro where is the link for the repository
hey how to load kaggle dataset to colab?
how to use model.h5 file to make predictions ???? , I tried using load_model but it's expecting checkpoints file, also tried load_weights but still giving error can u pls show how to use this model.h5 file to make predictions ??????????
You can use `get_caption_model` function to load the model: github.com/pritishmishra703/Image-Captioning/blob/master/model.py#L299
Then to make predictions use `generate_caption` function: github.com/pritishmishra703/Image-Captioning/blob/master/model.py#L270
hi can you help me please,, when i call get_caption_model() function i get the following error "ValueError: axes don't match array" do you you have any ideas
Can you please paste the entire error.
I also have this same error. Do you know how to solve it.
Hi, I tried testing your model and it was not giving correct captions most of the time like whenever I uploaded a simple face image, it would always prompt "a man in a suit and tie". I am new to ML/DL and wanted to make my first project on this topic. How can I make it prompt more accurate with diverse captions?
You mentioned that you used 14k images, Does using the whole COCO dataset increase its caption accuracy?
I haven't tried training it on whole dataset but i am sure that the caption accuracy will increase if you do it. Make sure the model doesn't overfit. This may increase the generalization capabilities of the model.
@@PritishMishra Okay I'll give that a try. In project building, Should I opt for a pre-trained model like ViT model from hugging face and use Pytorch for processing. The whole project is completed within 30 lines of code and the accuracy is extremely high as well. Do let me know your thoughts on that.
@@blackplagueklan7246 can you share the notebook with me? I want to see the performance. I will be glad to share the link with everyone in description!
dude can you share me the notebook please@@blackplagueklan7246
RNN file does not exist bro pls upload
Can you use BLEU score for evaluate the model
Sure i will keep this in mind next time.
Hi, I just replicated your code with Coco and the transformers but the accuracy is no more than 43%. You know why?
The Image Captioning model is a generative model, which means that it predicts a new caption for each image. You may be aware that the predictions are generated word by word; the model generates new words depending on the words it predicted previously, and generative models are highly chaotic; a minor change in their initial conditions can completely affect the structure of the predicted captions. That's why, accuracy is a hard metric to use when evaluating such models because even a single extra word in the model's prediction might entirely ruin the accuracy. In short, 43% is moderately good accuracy for our model.
can u help me out man?
can you share the github link for prediction purposes based on loaded model
Check description.
How can I contact you?
How to open a browser in Google colab
I want to know how you built the webapp
You can find the code on HuggingFace. I have used Streamlit.
Can we make this for real time images from webcam
Yes. You can do it by using OpenCV.
Hello ,is anyone was able to train the model on the all data... If so can you please please share the model.h5 gile
goog one buddy
Can we use the same code with Arabic language?
Definitely. You just have to train it on Arabic dataset.
Brother this video is really great and i loved your explanation but i am a beginner in aiml and want to learn this in detail
Can you please create a detail video on this topic
got error context.txt file
Can I know the error?
Sexy explanation bhai
Majja agaya😌💫
nailed it
cool
"with open(f'{BASE_PATH}/annotations/captions_train2017.json', 'r') as f:" what is this path in the code???? i can not get it and it is showing me directory error
pllzzz reply me i m stuck since long!!
i m geeting directorary error in each code
Hello, I originally made that notebook on Kaggle. So I forgot to include that downloading code on colab. I'm doing it right now. However, I strongly advise you to run that file on Kaggle because the coco dataset is 27 GB and downloading it on colab will take forever. So, to execute the file on Kaggle, do the following:
1. Download the notebook from colab. (Go to File -> Download -> Download .ipynb)
2. Go to Kaggle and sign in.
3. Then, on the left menu, click the big "+" button.
4. Select "Create Notebook."
5. You should now be able to see the newly created notebook. Now, Go to File -> Import Notebook
6. Upload the file you downloaded in Step 1.
7. You should now be able to see the entire notebook. Now, on the right pane, click the "Add Data" button.
8. Look for Awsaf's "Coco 2017 Dataset" and add that dataset. (This one: bit.ly/3Vcst64)
You're good to go! Run the notebook now, and everything should be fine. If you encounter any new errors, please reply here and I will help you.
Hello
Please reply
Source code link with RNN not working😢😢
Bro the Image Captioning with RNN source code is not available
I will fix this and get back to you.