Idk how many videos I went over but not a single one would say that partition in Kafka is JUST A QUEUE. They would unnecessarily make it complicated with more technical jargon. Thank You good Sir🧔♂👋🎩
James, this is a great video. It goes to enough technical details and a perfect first video on Kafka. It should have a million views, really. Please keep posting and sharing your knowledge. Thank you.
I love how you don't just jump into the current implementation, but rather, goes through the thought process of starting out with single server setup, addressing issues, and then leading up to how Kafka handles it. Nice video. The videos help, the explanations are crystal clear and detailed too.
What on earth was that? The most useful introduction I encountered to watch. Not only it addresses a lot of technical Q&As but also does it in a visual, perceptive and intuitive manner!
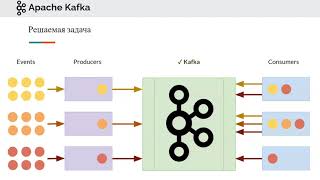
Transcript: Apache Kafka is the answer to the problems faced by the distribution and the scaling of messaging systems let me try to illustrate this by an example imagine we were to design a system that listens to various basketball game updates from various sources such updates might include game scoring participants and timing information it then displays the games status on various channels such as mobile devices and computer browsers in our architecture we have a process that reads these updates and writes them in a queue we call this process a producer since it's producing these updates onto the queue at the head of this queue a number of downstream processes consume these updates to display them on the various channels we call these processes consumers over time we decide to expand and start following more and more games the problem is that our servers are now struggling to handle the load this is mainly because the queue is hosted on one server which is running out of memory and processing capacity our consumers are also struggling in a similar fashion so now we start thinking of how we can add more computing power by distributing our architecture but how do we go about distributing AQ data structure by its nature the items in a queue follow a specific ordering we could try to randomly distribute the contents of the queue onto multiple ones if we do this our consumers might consume the updates in the wrong order this would result in inconsistencies for example the wrong scoring being displayed across the channels one solution is to let the application specify the way to distribute the items in the queue in our example we could distribute the items using the match name meaning that the updates coming from the same match would be on the same queue this strategy would maintain an ordering per basketball match this is the basic fundamental difference of Kafka from other messaging systems that is item sent and received Kafka require a distribution strategy let's have a look at some more detail and terminology used in Kafka each one of these queues is called the partition and the total number of partitions is called a partition count each server holding one or more of these partitions is called a broker and each item in a partition is called a record the field used decide which partition the record should be stored in it's called the partition key it's up to the application to decide which field to use as the partition key if no key is specified Kafka simply assigns a random partition a grouping of partitions handling the same type of data is called a topic in order to identify each record uniquely Kafka provides a sequential number to each record this is called an offset essentially a recording that topic is identified by a partition number and an offset in our application since we have now distributed our data in the topic using the name as the partition key we can now also parallelize our consumer applications having one consumer per partition guarantees ordering per game consumers can live on one machine or distributed amongst multiple ones one important concept in Kafka is that consumers are very lightweight and we can create many of them without affecting performance this is mainly because Kafka only needs to maintain the latest offsets read by each consumer typically consumers read one record after the other and resume from where they left after a restart however in Kafka it's up to the consumer implementation to decide on how to consume records it's quite common to have consumers to read all the records from the beginning on startup or to read the record in different orders such as reading back to front for example in Kafka each consumer belonging to the same consumer group do not share partitions this means that each consumer would read different records from the other consumers multiple consumer groups are useful when you have different applications reading the same contents in our example we could have a consumer group called mobile and another consumer group called computer these groups will read the same records but update different channels each consumer in these groups will have separate offset pointers to keep track which latest record was read if consumers can read using custom ordering how can Kafka determine that the record has been consumed and it can safely delete that record so it can free up space the answer is that tough comp provides various policies that allow it to do a record cleanup for example using irritation policy you can provide a record age limits say 24 hours after which the records are automatically deleted using this policy if your consumer application is never down for more than this age limit no messages are lost another capability of Kafka is to store records in a fault tolerant and durable way each record is stored on persistent storage so that if a broker goes down it can recover when it comes back up additionally Kafka replicates partitions so that when a broker goes down a backup partition takes over and processing can resume this replication is configured using a replication factor for example a replication factor of three leads to three copies of a partition one leader and two backups this means that we can tolerate up to two brokers going down at the same time Kafka can be a solution to your scalability and redundancy problems if the problem is well stated and the technologies are well understood there are of course a lot more technical and implementation details which can be found on kafkas documentation I hope that this short video has been helpful at providing an introduction but the fundamental concepts in Kafka if you like it please give it a thumbs up and subscribe.
This is THE way to teach concepts as an introduction... I know because I already have questions about limitations and applications, and I'm thinking of a lot of other services that use something similar or actually are using K somewhere underneath; services I didn't REALLY understand, and now make much more sense. Thank you.
What a great video! Perfect balance between an illustrating example and technical depth. Easy to follow along. I tried another video before, with which started out talking about "source systems" and "target systems", never explaining what they mean by those, without any illustrating example, and that video lost me right away. In contrast, yours easily made sense from the first second and was easy to follow along as you kept adding depth incrementally.
This is exactly how an introduction to a tool should be made. Thanks James, liked and subscribed! I've seen a lot of these videos about user organisations and purpose, but not the exact problem they solved using this.
Hands-on Kafka in 35 minutes!! Checkout out this video playlist here: ruclips.net/p/PLSMAAT50NTjRqga9HqKdcA0J_I1h6aw_d , please do subscribe 😊so that I get motivated and keep giving good content.
What a fantastic video... Made very very simple. 4:25 was little tough to understand. all others were made very very simple and easy to understand. You are amazing
Wow! You created a great video - informative and concise. It gives enough technical details, but not too many in a short amount of time. Rarely do you see technical videos this well made on RUclips. Thank you.
Very straightforward explanation and easy translation of essential Kafka concepts with the "real" meaning of them! Loved the basketball streaming example! It would be great for future videos if you could slow down a bit, I sometimes needed to stop the video in order to let some ideas sink 😉
Thorough Notes Apache Kafka is a solution to the problems faced by the distribution and scaling of messaging systems. Kafka is used to design a system that listens to various basketball game updates from various sources and displays the game's status on various channels such as mobile devices and computer browsers. In the architecture, a process called a producer reads these updates and writes them in a queue. Downstream processes called consumers consume these updates to display them on the various channels. As the system expands to follow more games, the servers struggle to handle the load due to the queue being hosted on one server which is running out of memory and processing capacity. To add more computing power, the architecture needs to be distributed. However, distributing a queue data structure can lead to consuming updates in the wrong order, resulting in inconsistencies. Kafka allows the application to specify the way to distribute the items in the queue. In the example, items are distributed using the match name, ensuring that updates from the same match are on the same queue, maintaining an ordering per basketball match. Each queue in Kafka is called a partition, and the total number of partitions is called a partition count. Each server holding one or more of these partitions is called a broker. Each item in a partition is called a record. The field used to decide which partition the record should be stored in is called the partition key. If no key is specified, Kafka assigns a random partition. A grouping of partitions handling the same type of data is called a topic. Each record in a topic is identified by a partition number and an offset. Kafka allows for parallelizing consumer applications, with one consumer per partition guaranteeing ordering per game. Consumers can live on one machine or distributed amongst multiple ones. Consumers in Kafka are lightweight and many can be created without affecting performance. Kafka only needs to maintain the latest offsets read by each consumer. Consumers belonging to the same consumer group do not share partitions, meaning each consumer reads different records from the other consumers. Kafka provides various policies that allow it to do a record cleanup. For example, using a retention policy, you can provide a record age limit after which the records are automatically deleted. Kafka stores records in a fault-tolerant and durable way. Each record is stored on persistent storage so that if a broker goes down, it can recover when it comes back up. Kafka replicates partitions so that when a broker goes down, a backup partition takes over and processing can resume. This replication is configured using a replication factor.
Clear explanation in 6 minutes...this is the best video to understand how Kafka works and what it solves...thanks...Can you also make a video comparing Kafka with JMS queues?
Excellent video, don't know how you did it, but you included all the core concepts in under 7 minutes. Great introduction or review for someone like me that is a bit rusty on the topic.
The concepts are explained briefly but clearly. You have done in 6 minutes what most other "gurus" on yt are not able to do in 30 minutes. They go on talking and talking without really being able to hit the keys, probably because they don't themselves understand it.
Wow this is a great video ! I am about to take couple of virtual onsite interviews for data engineer role and looking for a short video to explain Kafa.. This is the best video !! Thanks
thank you for all the hard work. this is vary informative. ps. could you please tell me what is the application/s used to create the infographics images









Idk how many videos I went over but not a single one would say that partition in Kafka is JUST A QUEUE. They would unnecessarily make it complicated with more technical jargon.
Thank You good Sir🧔♂👋🎩
I felt the same ,bro 👍
Hours of Kafka technology within 6 mins. And that too crystal clear. Hats off.
Finally a tutorial using examples instead of abstract concepts. Thanks!
New kafka practical tutorial ..ruclips.net/video/mlH0y7FOukU/видео.html
This 6 minutes made my day! What a crisp explanation. No bullshit straight and on point.
James, this is a great video. It goes to enough technical details and a perfect first video on Kafka. It should have a million views, really. Please keep posting and sharing your knowledge. Thank you.
New kafka practical tutorial ..ruclips.net/video/mlH0y7FOukU/видео.html
You are right 👍
It has now
I love how you don't just jump into the current implementation, but rather, goes through the thought process of starting out with single server setup, addressing issues, and then leading up to how Kafka handles it. Nice video. The videos help, the explanations are crystal clear and detailed too.
What on earth was that? The most useful introduction I encountered to watch. Not only it addresses a lot of technical Q&As but also does it in a visual, perceptive and intuitive manner!
Transcript: Apache Kafka is the answer to the problems faced by the distribution and the scaling of messaging systems let me try to illustrate this by an example imagine we were to design a system that listens to various basketball game updates from various sources such updates might include game scoring participants and timing information it then displays the games status on various channels such as mobile devices and computer browsers in our architecture we have a process that reads these updates and writes them in a queue we call this process a producer since it's producing these updates onto the queue at the head of this queue a number of downstream processes consume these updates to display them on the various channels we call these processes consumers over time we decide to expand and start following more and more games the problem is that our servers are now struggling to handle the load this is mainly because the queue is hosted on one server which is running out of memory and processing capacity our consumers are also struggling in a similar fashion so now we start thinking of how we can add more computing power by distributing our architecture but how do we go about distributing AQ data structure by its nature the items in a queue follow a specific ordering we could try to randomly distribute the contents of the queue onto multiple ones if we do this our consumers might consume the updates in the wrong order this would result in inconsistencies for example the wrong scoring being displayed across the channels one solution is to let the application specify the way to distribute the items in the queue in our example we could distribute the items using the match name meaning that the updates coming from the same match would be on the same queue this strategy would maintain an ordering per basketball match this is the basic fundamental difference of Kafka from other messaging systems that is item sent and received Kafka require a distribution strategy let's have a look at some more detail and terminology used in Kafka each one of these queues is called the partition and the total number of partitions is called a partition count each server holding one or more of these partitions is called a broker and each item in a partition is called a record the field used decide which partition the record should be stored in it's called the partition key it's up to the application to decide which field to use as the partition key if no key is specified Kafka simply assigns a random partition a grouping of partitions handling the same type of data is called a topic in order to identify each record uniquely Kafka provides a sequential number to each record this is called an offset essentially a recording that topic is identified by a partition number and an offset in our application since we have now distributed our data in the topic using the name as the partition key we can now also parallelize our consumer applications having one consumer per partition guarantees ordering per game consumers can live on one machine or distributed amongst multiple ones one important concept in Kafka is that consumers are very lightweight and we can create many of them without affecting performance this is mainly because Kafka only needs to maintain the latest offsets read by each consumer typically consumers read one record after the other and resume from where they left after a restart however in Kafka it's up to the consumer implementation to decide on how to consume records it's quite common to have consumers to read all the records from the beginning on startup or to read the record in different orders such as reading back to front for example in Kafka each consumer belonging to the same consumer group do not share partitions this means that each consumer would read different records from the other consumers multiple consumer groups are useful when you have different applications reading the same contents in our example we could have a consumer group called mobile and another consumer group called computer these groups will read the same records but update different channels each consumer in these groups will have separate offset pointers to keep track which latest record was read if consumers can read using custom ordering how can Kafka determine that the record has been consumed and it can safely delete that record so it can free up space the answer is that tough comp provides various policies that allow it to do a record cleanup for example using irritation policy you can provide a record age limits say 24 hours after which the records are automatically deleted using this policy if your consumer application is never down for more than this age limit no messages are lost another capability of Kafka is to store records in a fault tolerant and durable way each record is stored on persistent storage so that if a broker goes down it can recover when it comes back up additionally Kafka replicates partitions so that when a broker goes down a backup partition takes over and processing can resume this replication is configured using a replication factor for example a replication factor of three leads to three copies of a partition one leader and two backups this means that we can tolerate up to two brokers going down at the same time Kafka can be a solution to your scalability and redundancy problems if the problem is well stated and the technologies are well understood there are of course a lot more technical and implementation details which can be found on kafkas documentation I hope that this short video has been helpful at providing an introduction but the fundamental concepts in Kafka if you like it please give it a thumbs up and subscribe.
Only a person who has deep knowledge on a subject can explain anything with clarity in a short video. Looking forward to more videos from you!
What an explanation. In 6 minutes so many details and so clear. This requires real talent
Simple, clear and concise.. That's how teaching should be.. Kudos!
It started off clear, but got very confusing after half way.
@@fieryscorpion same feeling
but it seems like I am too stupid for now to understand the second part. this might be the reason
This is THE way to teach concepts as an introduction... I know because I already have questions about limitations and applications, and I'm thinking of a lot of other services that use something similar or actually are using K somewhere underneath; services I didn't REALLY understand, and now make much more sense. Thank you.
Would love to see more Kafka subjects communicated this way, awesome to give to a team to get basic concepts down.
As Einstein said - 'If you can't explain it simply, you don't understand it well enough.' Perfect explaination for a beginner. Thanks much.
New kafka practical tutorial ..ruclips.net/video/mlH0y7FOukU/видео.html
What a great video! Perfect balance between an illustrating example and technical depth. Easy to follow along.
I tried another video before, with which started out talking about "source systems" and "target systems", never explaining what they mean by those, without any illustrating example, and that video lost me right away. In contrast, yours easily made sense from the first second and was easy to follow along as you kept adding depth incrementally.
Straightforward explanation in six minutes, thank you.
This is exactly how an introduction to a tool should be made. Thanks James, liked and subscribed! I've seen a lot of these videos about user organisations and purpose, but not the exact problem they solved using this.
I was so struggling to understand why Kafka and this is it! to the point and crisp clear explanation . Thankyou !
Hands-on Kafka in 35 minutes!! Checkout out this video playlist here: ruclips.net/p/PLSMAAT50NTjRqga9HqKdcA0J_I1h6aw_d , please do subscribe 😊so that I get motivated and keep giving good content.
Watched many videos on Kafka but this is what i was looking for. Thanks for the simple yet effective tutorial for beginners. Loved it.
Shruti
One of the best explanation of KAFKA to understand simply
the most clear explanation of kafka I ve seen
AGREE,
I really appreciate the simple and clear explanation!
Hours of knowledge, juiced up in 6 minutes. Amazing video
Best and easy summary on Kafka. Pls keep posting useful videos like this.
What a fantastic video... Made very very simple. 4:25 was little tough to understand. all others were made very very simple and easy to understand. You are amazing
Great explanation Sir 🙏from India 🇮🇳..will follow your classes from now❤
Wow! You created a great video - informative and concise. It gives enough technical details, but not too many in a short amount of time. Rarely do you see technical videos this well made on RUclips. Thank you.
Best intro to Kafka video I've seen. Thank you.
This is the fantastic video I ever watched on Kafka understanding.
It was very well presented, in a simple and effective way. This put me on the page about Kafka technology.
Thank you so much for this video. Summarizes the general concepts brilliantly.
This is the best video hands down! I can see why Kafka is widely preferred because it's amazing distributed and fault tolerant architecture
Very straightforward explanation and easy translation of essential Kafka concepts with the "real" meaning of them! Loved the basketball streaming example! It would be great for future videos if you could slow down a bit, I sometimes needed to stop the video in order to let some ideas sink 😉
Excellent Video, in just 6 mins you have covered core concepts of the Apache kafka.
Thorough Notes
Apache Kafka is a solution to the problems faced by the distribution and scaling of messaging systems.
Kafka is used to design a system that listens to various basketball game updates from various sources and displays the game's status on various channels such as mobile devices and computer browsers.
In the architecture, a process called a producer reads these updates and writes them in a queue. Downstream processes called consumers consume these updates to display them on the various channels.
As the system expands to follow more games, the servers struggle to handle the load due to the queue being hosted on one server which is running out of memory and processing capacity.
To add more computing power, the architecture needs to be distributed. However, distributing a queue data structure can lead to consuming updates in the wrong order, resulting in inconsistencies.
Kafka allows the application to specify the way to distribute the items in the queue. In the example, items are distributed using the match name, ensuring that updates from the same match are on the same queue, maintaining an ordering per basketball match.
Each queue in Kafka is called a partition, and the total number of partitions is called a partition count. Each server holding one or more of these partitions is called a broker. Each item in a partition is called a record.
The field used to decide which partition the record should be stored in is called the partition key. If no key is specified, Kafka assigns a random partition.
A grouping of partitions handling the same type of data is called a topic. Each record in a topic is identified by a partition number and an offset.
Kafka allows for parallelizing consumer applications, with one consumer per partition guaranteeing ordering per game. Consumers can live on one machine or distributed amongst multiple ones.
Consumers in Kafka are lightweight and many can be created without affecting performance. Kafka only needs to maintain the latest offsets read by each consumer.
Consumers belonging to the same consumer group do not share partitions, meaning each consumer reads different records from the other consumers.
Kafka provides various policies that allow it to do a record cleanup. For example, using a retention policy, you can provide a record age limit after which the records are automatically deleted.
Kafka stores records in a fault-tolerant and durable way. Each record is stored on persistent storage so that if a broker goes down, it can recover when it comes back up.
Kafka replicates partitions so that when a broker goes down, a backup partition takes over and processing can resume. This replication is configured using a replication factor.
this is way better than the other kafka in 5mins video on youtube
Simple clear and concise. Thank you James
view a lot of videos about kafka, and you 're video is the best one
I just needed to watch it to become clear. Thanks a lot.
Best kafka intro so far. great video. thanks a lot
Clear explanation in 6 minutes...this is the best video to understand how Kafka works and what it solves...thanks...Can you also make a video comparing Kafka with JMS queues?
I was searching up Franz Kafka but this is interesting as well
Your way of explanation is Outstanding!!
Thanks and keep the good work flowing
Best explanation under 7 minutes!!
❤ Wohoooooo! Simplicity at its peak. Thanks for explaining Kafka in a simplistic way.
Very Helpful, explained in a very cleaned way. Thanks James for sharing this.
100% Perfect introduction to Kafka
Very simple concise explanation!!
James very simple and easy to understand
This was extremely well done. You've earned a sub.
This is a perfect video explaining the core concepts of Kafka
Thank you so much for the this video. The diagrams really helped me understand this better.
Please make more such videos. Your content is good. Thank you for bringing this. The video is to the point.
it is really easy to get basic things of Apache Kafka
Thanks
Really amazing video, I've subscribed without thinking about it.
Really concise overview of Kafka. Thank you.
Hands down the best video introduction to understanding kafka in 6 mins, liked and subscribed
Great intro to the fundamentals! Great use of example too
Straightforward and intuitive video. Thx!!!
Thank you for the detailed example with the matches and the visualization, it really helps to understand the topic intuitively. Keep it up, James!
Thanks, James... Please post more videos. Precise and clear
Excellent video, don't know how you did it, but you included all the core concepts in under 7 minutes. Great introduction or review for someone like me that is a bit rusty on the topic.
New kafka practical tutorial ..ruclips.net/video/mlH0y7FOukU/видео.html
This is the best explanation I have found on internet on the topic
many thanks :)
Its crazy how good this video is
The concepts are explained briefly but clearly. You have done in 6 minutes what most other "gurus" on yt are not able to do in 30 minutes. They go on talking and talking without really being able to hit the keys, probably because they don't themselves understand it.
you explained it so nicely and in a simple way.
Wow this is a great video ! I am about to take couple of virtual onsite interviews for data engineer role and looking for a short video to explain Kafa.. This is the best video !! Thanks
Great video. Although I never use Kafka before, it is very clear for me to understand the its mechanism under the hood. Thank you.
Damn. Finally a good video on Kafka. Thank you!
Great and very good summary of Kaffka in small amount of time
James what a Content with everything ..Thanks !! keep uploading
James, really liked this tutorial! Concise with fantastic illustrations. Bravo
Really very simple, and complete, description of Kafka. Thx!. Subscribed
Amazing "nutshell" intro to kafka. thanks.
To add Kekfa helps to achieve 2 main goals
1. Use Ques for async communication
2. Achieve a pub-sub model
Best explanation on Kafka
the basic terms explained very very well.. Thank you.
Thank you sir very simple and informative explanation
James, thank you so much for this video. I love Basketball too and so it particularly appealed to me.
Very clear and interesting way that you present the content. Got sparked to kafka rrright here. :D
Great video this
Had a hard time understanding the fundamentals of how it works.
Thank you sir for explaining with example.
Love the brevity of the video !
Better than brilliant very well organized
you have such a nice friendly voice thx
Great video! Very clear explanation!
This is a good video. This is what I've been looking for.
Looking for more content like this. Thanks!
Simple, clear and concise.
New kafka practical tutorial ..ruclips.net/video/mlH0y7FOukU/видео.html
This Video worth Million dollar
Very well explained. keep up the good work. Your videos will help a lot.
Amazing example, great graphics and very neat explanation. Thank u for the video!
thank you for all the hard work. this is vary informative.
ps. could you please tell me what is the application/s used to create the infographics images
Excellent video, great explanation and visual representation. Amazing job!
such a great video with great explanations and examples. learned a lot!! thanks!!!!
Very well done man, simplified demonstration
you earned my subscription due to this.
loved it ! simply explained , to the point .Thankyou
Amazing. You just reduced 50 hours of research for me ❤