I've watched other videos of his, and he is so good at teaching. He's always explaining "WHY" with the simplest words. Also, very concise examples. Having watched thousands of videos teaching data science, he is the best ever and I wish he would keep it going. Thank you!
Thanks to this video I finally figured it out! This is definitely one of the best videos in which Word2Vec is intuitively explained with a simple example.
i take hour to hour to read many article and watch many videos but still not get clear. but your 10 min videos help me figure out everything's. thanks you so much sir.
Are you kidding me ? I tried to learn from Andrew Ng, but could not grasp what he said, you on other hand made this look so fucking easy. OMG! Thank you!!!
A great video and wonderful explanation. Just 1 change I would like to suggest: While you are converting word to label, you are using the following line for neighbor in sentence[max(idx - WINDOW_SIZE, 0) : min(idx + WINDOW_SIZE ,len(sentence))+1] : here instead of adding +1 to the end of min() function, you should add it to only min()'s first argument only. what i mean is for neighbor in sentence[max(idx - WINDOW_SIZE, 0) : min(idx + WINDOW_SIZE+1, len(sentence))] : your method does not raise error, as python will look only till last index and ignore number higher than that. But the suggested method wont raise error incase if someone tries to access it by index rather than its value.
Thank you for the video and the explanation :) Just one note: In the 21th century, it would be very nice to finally find other examples as those, which we have trained and educated by for centuries. its so demotivating to see/hear/read again this same assignments man-brave and woman-beautiful like in the more then 100 years old fairy tales. lets go for better examples, which are inclusive and lets everybody participate equally! :) thank you!
Please make an explanation on more advanced topics in NLP (e.g t-SNE). The explanation is one of the best on the RUclips. Without abstract concepts. Straight to the point. Love that guy =)
awesome job, this is the best explanation I've seen so far! Can you make a video to other word embedding methods like glove, wordrank and word2gauss, please?
Abu Bakar Siddiqur Rahman Rocky hi, my code word2vec has only two dimensions while popular word2vec uses 300 dimensions, that should be most reason why it doesn’t work well on long sentence. 2 dimensions may not enough space to store similarities of long sentences. I used two dimension to visualize similarities, if you want to use word2vec for long sentence, you can try 300 dimension or use pretrained word2vec. Thanks.
@@TheEasyoung Thank you for your reply. I'll try with 300 embedding dimensions. But the problem is its not working in this section: for x, y in zip(df['input'], df['label']): X.append(to_one_hot_encoding(word2int[ x ])) Y.append(to_one_hot_encoding(word2int[ y ])) when I run this section, my PC get hanged.
It is hard to debug from my side, but I suggest you may want to run with small amount of data first to see if t is either code or data problem. Thanks.
Thanks for this simple explanation. My question is, what is the word embedding then? The activated hidden layer or the weight of the hidden layer from input to hidden layer?
You have explained it very well! I had many doubts before and all of them are clear now. I have a request for you, could you please make a video focusing more on how to train model with word2vec? I would be grateful to you! :)
The window size defined is confusing, for example for window size 1, we take words before and after the word of our interest and for window size two shouldn't it be two words before and after? The example shown there doesn't show it. Would help a lot if this is addressed.
Awesome tutorial. But I wonder is that possible to pull out the vectors to txt file with format that each token followed by its vectors just like the format of either 'word2vec-google-news' or 'glove.6b.50d'.
Thank you, I got a lot of information about NLP from this tutorial. But I am confused about the embedding values [1,1] Word2Vecor embedding column. Can anyone explain where from these values comes? The same column is shown at 1:25. Thanks in advance
Good Video, can you explain to me, how we can get vector for one document like a tweet, but vector for just one word. I want to use word2vec as a feature for sentiment analysis.
you can use word2vec as input to your model and use the final vector from sentence as sentence vector. for example, if you use RNN for sentiment classification, you can think the final state as sentence vector.
@@TheEasyoung is it different from averaging vector? I have read on some articles in internet which explain about that if want to get the document or sentence vector? Thanks so much for responding my comment 🙂🙂🙂
Do you think, we can do document similarity of one speech to another speech? Given that I would fit text of speeches giving by Actor A in rows X [multiple speeches] and speeches of Actor B in next column in rows as well - a number of speeches would be same so I could so paraell comparison and write the result for each row. Something like text2vec in R. It has vectors as well however it seems its not yet supported completely for pareel similarity. And I am totally lost in Python, tried it several times without a success.
Do you guys have any text about server processing about this tool? Is it possible to use it with easy for big audiences and text volume analysis? Thank you!
안녕하세요. 영상 잘 봤습니다!! 궁금한것이 하나 있습니다. 기존의 TF-IDF나 동시 발생 행렬같은 통계 기반 임베딩 기법의 경우 king + man - woman = queen 과 같은 문제를 해결 못하나요? 기존 통계 기법보다 word2vec이 좋은 부분은 데이터량 말고 뭐가 있나요?
I lost in the woods after the first time word 'entropy' arrived ( 07:00 aprox ). Would be nice to add an explanation for it as it was done for everything before...
Vinay Kumar dedup input will help back propagation. Repeating input won’t make multi weight since each word represented by unique one hot encoding at the beginning. Thanks!




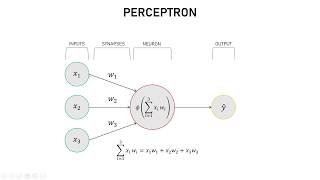





Crystal clear and brief to the point. Well done.
I've watched other videos of his, and he is so good at teaching. He's always explaining "WHY" with the simplest words. Also, very concise examples. Having watched thousands of videos teaching data science, he is the best ever and I wish he would keep it going. Thank you!
Thanks to this video I finally figured it out! This is definitely one of the best videos in which Word2Vec is intuitively explained with a simple example.
Among the videos I've watched so far, this was the one that explained the topic the best.
i take hour to hour to read many article and watch many videos but still not get clear. but your 10 min videos help me figure out everything's. thanks you so much sir.
Are you kidding me ? I tried to learn from Andrew Ng, but could not grasp what he said, you on other hand made this look so fucking easy. OMG! Thank you!!!
Simple, Smooth, and Crystal Clear. Great Work!
The first time I have a great understanding
Never been simpler like this
Finally a good and clear explanation on what word2vec is. Thank you.
Awesome explanation. Do more videos about NLP and deep learning
A great video and wonderful explanation.
Just 1 change I would like to suggest:
While you are converting word to label, you are using the following line
for neighbor in sentence[max(idx - WINDOW_SIZE, 0) : min(idx + WINDOW_SIZE ,len(sentence))+1] :
here instead of adding +1 to the end of min() function, you should add it to only min()'s first argument only. what i mean is
for neighbor in sentence[max(idx - WINDOW_SIZE, 0) : min(idx + WINDOW_SIZE+1, len(sentence))] :
your method does not raise error, as python will look only till last index and ignore number higher than that. But the suggested method wont raise error incase if someone tries to access it by index rather than its value.
Best, concise and clear explanation on the subject. Well done.
Haven't seen any tutorial video better than this.. What a nice and crisp explanation :) Big thank u Minsuk :)
Thank you for the video and the explanation :) Just one note: In the 21th century, it would be very nice to finally find other examples as those, which we have trained and educated by for centuries. its so demotivating to see/hear/read again this same assignments man-brave and woman-beautiful like in the more then 100 years old fairy tales. lets go for better examples, which are inclusive and lets everybody participate equally! :) thank you!
Your explanation and demo are awesome!
Giving so much information under 10 minutes : Awesome!!!
Wow, after digging thru so many videos i just hit my jackpot
Thank you so much, after those bad word2vec lectures and tutorial video
This is like a revelation come to me, what a great explanation
This was a very good Video, Well done Sir
One of the best explanation i ever had. Bulls Eye. Thanks for this video
Excellent video ... Very simple and clear demonstration !!!
Very simple and best explanation
Simple yet very powerful explanation!!! :) thank you so much for video
Please make an explanation on more advanced topics in NLP (e.g t-SNE). The explanation is one of the best on the RUclips. Without abstract concepts. Straight to the point. Love that guy =)
A very simple to understand video with a working example - just what I wanted. Thank you :)
Thanks, it was very helpful to understand after viewing lots of videos and tutorials.
Simple and clear! great work Minsuk!
Simple, Easy and to the point!!! Thnx a lot!!!
Really appreciate it. It was very helpful. Thank you
A great introduction and detailed explanation to word2vec!
the best introduction of word2vec!
Extraordinary clear. Excelent video!
that was such a nice explanation ,thanks a lot
wow, thank you ! really appreciate your efforts to make these tutorials
Awesome.. clear explanation.
Thanks. Now I know what is Word2Vec
That's an excellent explanation. Keep up the good work!
Thank you for the great explanation! This really helps my with preparing for an exam
Best explanation. Wish the implementation was done with keras.
One of the videos worth watching regarding the topic. Thank you.
Clear explanation and good example.
Thank you for so clear explanation!
Awesome explanation and visuals. Thanks for taking the time to create them. Cant wait to check out rest of the videos
Thank you, nice explanation and presentation material
best explanation........Thank You
I just start learning about word2Vec I feel like I'm already familiar with the subject haha Thank you Minsuk
Beautiful Explanation.. Thanks
Great explanation, sir!
This is so well explained. Thank you so much!
Thank you so much, now I cleary know what embedding is!!
GodLike Explanation
liked and subscribed.
really well done.
This was fantastic! Finally understood it.
Very clear... perfect explaination. :)
Thank you very much sir! Great explanation.
Thanks for posting this amazing tutorial video :)
Nice Explanation...Thank You
Thank you for the great explanation!
You nailed it man... Great work.. And thanks 👍
Thanks for explaining very clearly
awesome job, this is the best explanation I've seen so far! Can you make a video to other word embedding methods like glove, wordrank and word2gauss, please?
Your video is amazing!
Very succinct and clear.
Good explanation!!
Thank you very much!!
you are just the best
Amazing!!! Well explained.
the best tutorial found
Very helpful, thank you so much!
Excellent work! Thanks.
amazingly explained!!!!!👌👌
Hi Minsuk Heo, I've a question. why this code is not run for a long corpus? Could anyone please answer me? Thanks for the excellent explanation.
Abu Bakar Siddiqur Rahman Rocky hi, my code word2vec has only two dimensions while popular word2vec uses 300 dimensions, that should be most reason why it doesn’t work well on long sentence. 2 dimensions may not enough space to store similarities of long sentences. I used two dimension to visualize similarities, if you want to use word2vec for long sentence, you can try 300 dimension or use pretrained word2vec. Thanks.
@@TheEasyoung Thank you for your reply. I'll try with 300 embedding dimensions. But the problem is its not working in this section:
for x, y in zip(df['input'], df['label']):
X.append(to_one_hot_encoding(word2int[ x ]))
Y.append(to_one_hot_encoding(word2int[ y ]))
when I run this section, my PC get hanged.
It is hard to debug from my side, but I suggest you may want to run with small amount of data first to see if t is either code or data problem. Thanks.
@@TheEasyoung Thank you. Could you please check your email?
Sorry, I don’t check email for debugging individual issue due to multiple reasons. I hope you resolve your issue.
Thanks for this simple explanation. My question is, what is the word embedding then? The activated hidden layer or the weight of the hidden layer from input to hidden layer?
The weights of the hidden layer is the word embedding! :)
wow... simply amazing
You have explained it very well! I had many doubts before and all of them are clear now. I have a request for you, could you please make a video focusing more on how to train model with word2vec? I would be grateful to you! :)
Akshay Gaurihar thanks a lot, Any topic on deep learning will be in my channel and thanks for suggesting one topic!
Thank you for the inspiring lecture!
Nicely explained
excelent video
Very nice, thanks!
Great video! Really clear!
The window size defined is confusing, for example for window size 1, we take words before and after the word of our interest and for window size two shouldn't it be two words before and after? The example shown there doesn't show it. Would help a lot if this is addressed.
Awesome tutorial. But I wonder is that possible to pull out the vectors to txt file with format that each token followed by its vectors just like the format of either 'word2vec-google-news' or 'glove.6b.50d'.
Thank you, I got a lot of information about NLP from this tutorial. But I am confused about the embedding values [1,1] Word2Vecor embedding column. Can anyone explain where from these values comes? The same column is shown at 1:25. Thanks in advance
same question.
Very well explained, thx
Great thanks for this video. I have a question concerning w1, w2 ? Both weights represent the linear output in hidden layer as w*X+b1?
w1, w2 are w from w*X+b1
This is a good start but gets very complicated and inefficient for when you are training on a large dataset.
Thank you so much, insanely helpful !
clear. thankyou so much :)
Good Video, can you explain to me, how we can get vector for one document like a tweet, but vector for just one word. I want to use word2vec as a feature for sentiment analysis.
you can use word2vec as input to your model and use the final vector from sentence as sentence vector. for example, if you use RNN for sentiment classification, you can think the final state as sentence vector.
@@TheEasyoung is it different from averaging vector? I have read on some articles in internet which explain about that if want to get the document or sentence vector?
Thanks so much for responding my comment 🙂🙂🙂
very good explanation! can you send the slides please for referencing.
Good one
Do you think, we can do document similarity of one speech to another speech? Given that I would fit text of speeches giving by Actor A in rows X [multiple speeches] and speeches of Actor B in next column in rows as well - a number of speeches would be same so I could so paraell comparison and write the result for each row. Something like text2vec in R. It has vectors as well however it seems its not yet supported completely for pareel similarity. And I am totally lost in Python, tried it several times without a success.
정말 감사하다, 잘 설명했어요
Very impressive! Thanks
You are legendary
Do you guys have any text about server processing about this tool? Is it possible to use it with easy for big audiences and text volume analysis? Thank you!
جزاك الله كل خير علي هذا العمل
Excellent thanks
안녕하세요. 영상 잘 봤습니다!! 궁금한것이 하나 있습니다.
기존의 TF-IDF나 동시 발생 행렬같은 통계 기반 임베딩 기법의 경우 king + man - woman = queen 과 같은 문제를 해결 못하나요? 기존 통계 기법보다 word2vec이 좋은 부분은 데이터량 말고 뭐가 있나요?
통계 기반 방법으로도 해결됩니다. 다른점은 word2vec은 이웃 단어에서 정보를 얻고, generative하게 데이터에서 직접 정보를 얻는다는 점입니다. 통계 기반으로는 glove 벡터만 봐도 얼마나 성능이 우수한지 알 수 있습니다.
I lost in the woods after the first time word 'entropy' arrived ( 07:00 aprox ). Would be nice to add an explanation for it as it was done for everything before...
if the inputs are repeating won't we get multiple sets of weights for those input after backdrop?+Minsuk Heo 허민석
Vinay Kumar dedup input will help back propagation. Repeating input won’t make multi weight since each word represented by unique one hot encoding at the beginning. Thanks!