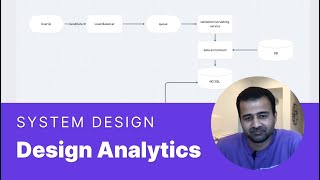
I strongly appreciated the trade-offs and the architecture insights discussed: 1. A hybrid approach combined Spark Streaming versus Apache Flink as distributed computing platforms, based on latency criteria for clickstream metrics. The justification being that Apache Spark streaming works well with >= 1 second metrics generation, whereas Apache Flink meets single millisecond / sub-second performance. 2. To use the push model ( agents and daemons ) versus the pull model ( the infra ) for large-scale data pipelines : the former being better for real-time needs ( even if it may overwhelms the pipeline ), whereas the latter is polling based and may fail to deliver real-time ( or close-enough-to-real-time ) customer behavior insights. 3. The justification for using a NoSQL DB versus a SQL DB for compute storage : NoSQL being schema-less, high-performant, and having low-latency reads and writes - and thus, able to handle large event volumes under ingestion ( e.g. Kafka's 50,000 events / second ), and how he identified the RDBMS storage as a potential pipeline bottleneck.
I thought this was too high level. There were no non functional requirements discussed. Also a lot of the complexity was abstracted with Lamdba usage. There should have been more discussion on some of the core functional requirements and non functional requirements and some more deep dives which this system design lacked.
We need more of these. However try to make it suitable for beginners or better still, state the experience in the title so we know whom this is directed to. Thanks
Great idea! We're actually working on this. Maybe adding "This is how a junior candidate answers. This is how a senior candidate answers." Hopefully rolling out soon. Stay tuned
Hey akshayshankar3707, we are planning to launch it in 1-2 months time. Join our waitlist so you get notified when it happens! www.tryexponent.com/courses/data-engineering









Join the waitlist for Exponent’s Data Engineering Interview Course: bit.ly/4cmpq34
I strongly appreciated the trade-offs and the architecture insights discussed:
1. A hybrid approach combined Spark Streaming versus Apache Flink as distributed computing platforms, based on latency criteria for clickstream metrics. The justification being that Apache Spark streaming works well with >= 1 second metrics generation, whereas Apache Flink meets single millisecond / sub-second performance.
2. To use the push model ( agents and daemons ) versus the pull model ( the infra ) for large-scale data pipelines : the former being better for real-time needs ( even if it may overwhelms the pipeline ), whereas the latter is polling based and may fail to deliver real-time ( or close-enough-to-real-time ) customer behavior insights.
3. The justification for using a NoSQL DB versus a SQL DB for compute storage : NoSQL being schema-less, high-performant, and having low-latency reads and writes - and thus, able to handle large event volumes under ingestion ( e.g. Kafka's 50,000 events / second ), and how he identified the RDBMS storage as a potential pipeline bottleneck.
I thought this was too high level. There were no non functional requirements discussed. Also a lot of the complexity was abstracted with Lamdba usage. There should have been more discussion on some of the core functional requirements and non functional requirements and some more deep dives which this system design lacked.
We need more of these. However try to make it suitable for beginners or better still, state the experience in the title so we know whom this is directed to.
Thanks
Great idea! We're actually working on this. Maybe adding "This is how a junior candidate answers. This is how a senior candidate answers."
Hopefully rolling out soon. Stay tuned
As per the changes/add, I think we could add the monitoring services there to see the system health and notify if any schema changes are important
I love this channel so much keep up the content :)!
When are you launching the data engineering course?
Hey akshayshankar3707, we are planning to launch it in 1-2 months time. Join our waitlist so you get notified when it happens!
www.tryexponent.com/courses/data-engineering
Likely in October! Finishing up some final lessons right now.