I think scaler should have separate course for Data engineering with Dsa and system design with industry level courses as most of guys are working in data engineer field than as Data science Waiting for such quality course to move into product based company
@@ankitKumar-js1ow Till now they do not have a plan/module for Data Engineering .They are simply not interested ..And what they have is DE is just not digestable
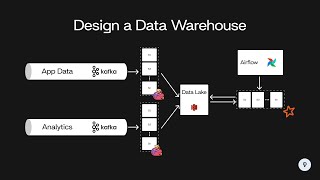
here is a summary: 00:57 - Understanding of data domains (example: finance data terminology, what is the relationship, primary key, foreign key. Give business side a clear image what can data engineers provide) 02:57 - Choosing data sources (example: sql database, distributed file system, API, sensor data, web application generated) 04:43 - Determine the data ingestion strategy( full load or incremental load) 08:37 - Design the data processing plan (pipeline design real-time process, or batch process) 11:11 - Set up storage for the pipeline output ( amazon s3 HDFS for datalake, AWS redshift, Hive for datawarehouse, dump back in transational databases) 13:19 - Plan the data workflow (scheduler, Apache airflow, apache nifi, Azkaban) 14:42 - Monitoring and governance tools (alert for pipeline failing, tools: Kibana, Grafana, DataDog, PagerDuty)
This is really really a very detailed and great explanation of end-to-end data pipeline building architecture. Hatsoff to your hardwork and putting this video out there for us brother. It will definitely clear the doubts and picture about how pipeline work for data migration/ingestion/integration based projects. Thanks a lot. 🙏









Check out our FREE masterclasses by leading industry experts now: bit.ly/3Apojjv
I think scaler should have separate course for Data engineering with Dsa and system design with industry level courses as most of guys are working in data engineer field than as Data science
Waiting for such quality course to move into product based company
@@ankitKumar-js1ow Till now they do not have a plan/module for Data Engineering .They are simply not interested ..And what they have is DE is just not digestable
Regular content. Can be easily searched over internet.
Haha
Paid Content is terrible .
@@sandeepdash5652 is it?
@@sanilkumarbarik9151 For DataEngineers its horrible ..not worth enough the time and money if you join for learning DE
Thank you for talking about a demo pipeline, this could come in handy in interviews.
Excellent presentation. Presented very nicely, concisely, and to the point.
Shashank just makes everything so easy to understand
Very well explained and all important topics were covered, thankyou for your efforts. Very helpful.
Thanks! Glad this was helpful! 😃
helps to see the big picture, thank you very much :)
Good one thanks
I just wanna say thank you for this video
here is a summary:
00:57 - Understanding of data domains (example: finance data terminology, what is the relationship, primary key, foreign key. Give business side a clear image what can data engineers provide)
02:57 - Choosing data sources (example: sql database, distributed file system, API, sensor data, web application generated)
04:43 - Determine the data ingestion strategy( full load or incremental load)
08:37 - Design the data processing plan (pipeline design real-time process, or batch process)
11:11 - Set up storage for the pipeline output ( amazon s3 HDFS for datalake, AWS redshift, Hive for datawarehouse, dump back in transational databases)
13:19 - Plan the data workflow (scheduler, Apache airflow, apache nifi, Azkaban)
14:42 - Monitoring and governance tools (alert for pipeline failing, tools: Kibana, Grafana, DataDog, PagerDuty)
This is really really a very detailed and great explanation of end-to-end data pipeline building architecture. Hatsoff to your hardwork and putting this video out there for us brother. It will definitely clear the doubts and picture about how pipeline work for data migration/ingestion/integration based projects.
Thanks a lot. 🙏
Thanks! Glad this was helpful! 😃
How can NOSQL (specifically Cassandra, MongoDB ) be good for ad-hoc analytical queries as mentioned during 12:05?
Thank you for brilliant video
Good content . Thank you🙏
Can't wait!
Well presented, thanks
Thank you! This was really helpful and well-explained.
Happy to hear that! 🙌🏼
Thanks scaler! 🔥
Thanks Shashank for explaining in very understandable manner,
But i have one question you have not discussed about Staging Area??
Awesome content 🙂
Thank you scaler
very nice.. thanks a ton!
Brilliant video again
thank you for the nice explanantion
Happy to hear that! 🙌🏼
Thanks
I easily understand this video
Make more vedios Gurudev thankyou very much
Awesome Video
Double like 👍🏽
Thank you
Grafana is a really good monitoring tool
Thank you.
Very nice content
Really good Content
As a data engineer, should you know all of these tech before getting a job or is it acquired during one?
you can easily get an entry level job in data engineering if you know good sql, basic python, basic cloud and hadoop architecture.
Very nice 🙂
When will complete Data Engineering course will be launched from Scaler?
Please 1 pipeline practical karke dikhao ...RUclips PE Aisa ek bhi vdo nhiye Jo big data ki pipe line create karke dikhaya ho...
Redshift is already setup on the cloud, what about Hive?
More Data engineering related content please
You guys did a great job.
Need full course for Data Engineer
🔥🔥🔥
Scaler knows what us students are searching for on google before an exam lol
Here the data source is MySQL, what if there was data coming in from multiple sources.
Data Modelling part was missed I guess
Bumb explanation.What he is explaining is based on his experience.Its not at all generic.He himself needs to improve
Aadha adhura gyan
Thank you for talking about a demo pipeline, this could come in handy in interviews.
Grafana is a really good monitoring tool