Это видео недоступно.
Сожалеем об этом.
Design a Fault Tolerant E-commerce System | System Design

HTML-код
- Опубликовано: 15 авг 2024
- Visit Our Website: interviewpen.c...
Join Our Discord (24/7 help): / discord
Like & Subscribe: / @interviewpen
This video dives into the fundamentals of designing fault tolerant systems--a critical skill to succeed in system design interviews. We'll dive into a basic e-commerce system and discuss all its failure modes and how to overcome them.
If you liked this video and want to learn more about fundamental systems and how they can be used to solve problems, check out our full course on interviewpen.c... !
Table of Contents:
0:00 - Introduction
0:50 - API Load Balancing
1:59 - Redundant Load Balancers
4:05 - Database Replication
5:17 - Third-Party Services
6:05 - Server Rack Failure
7:00 - Datacenter Failure
7:40 - Conclusion
7:53 - interviewpen.com
Socials:
Twitter: / interviewpen
LinkedIn: / interviewpen
Website: interviewpen.c...



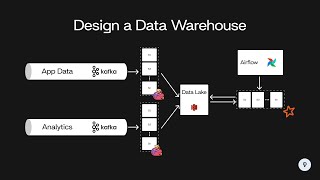





For the redundant load balancer section, you mentioned that it isn't a great solution because it introduce latency and less flexibility because of DNS cache. Then I'm wondering what is a good solution or some alternative solutions?
These problems are why we introduced a load balancer--failure of a load balancer should be much less likely than failure of an API node, so we can take advantage of that solution in most cases. Thanks for watching!
Great video! Would be cool to deep dive on a multi country/region E-Commerce solution.
We have multiple issues that are only noticed at larger scales.
--Like implementing the search feature or a ML powered product ranking.
Yep, tons and tons of problems to deal with in a full system--we have more in-depth problems on interviewpen.com . Thanks for watching!
Brilliant channel.
Thank you!
Thanks. What about the DB replication/synchronization across the regions, and the potential failure of network communications between them?
Yep, definitely a concern. A network partition between the two regions could cause a "split-brain" situation where the two regions end up with different states. Often we'd just have one region elected as a master to handle writes, with reads from other regions having eventual consistency. We have a cool video about this kind of stuff on interviewpen.com :)
Latency (and thus eventual consistency) is also a thing even if you use a single region replication. This needs to be also handled properly by the application.
Great video, I have a few questions thought if you don't mind:
1- How do the load balancers know the ip's of the API servers? Do the API servers ping the load balancer or they always on the same local network or something else?
2- Would the private DNS that routes from API to database, just be a simple intermediatry server hosted locally? Like a local mini load balancer?
Thank you for the valuable information!
1--Yes, the load balancer will health-check the API nodes by pinging or making HTTP requests to ensure liveness.
2--Essentially yes, although it's important to note that requests are not being routed through this server, it's just responsible for notifying the API about what is online.
Thanks for watching!
Solve the payment processing by switching to bitcoin only payments.
Do we need those when using AWS or GCP?
Depending on what services you use for your cloud infrastructure, some of this will be managed for you. However, it’s always important to understand fault tolerance and ensure the service you’re using meets your needs.
Could another load balancer be on standby for when a load balancer goes down and take its external IP address? Or is this scenario assuming something happened where that’s not possible like the data center going down
Yes, but there still has to be a fixed-size set of online load balancers to not interfere with the user experience.
How often you will have DB outage on cloud providers? And will another DB instance work at the same time. Also didn't see any options for multiplication of DB instances, only DB replicas for read operations. As for Payment API failor only way is a retry logic or error message to try later. Maybe there are also open websites we in live mode people can see failure status of the system
Most cloud providers have SLAs on their database solutions, and most offer replication to increase that SLA. Hope that helps!
but your methods are very ineffecient for small scale companies with low traffic
Small companies tend to start off with something like in the beginning of the video if fault tolerance isn't important :)
annnnnnnnnnnnd you infra cost will be 50k and need engineers worth 200k for maintainance
I have to say that most of these architectural things are useless unless you have unlimited resources.
Most companies tend to adopt the approach in the beginning of the video and scale to something more complex once it fails :)