Constrained parameters? Use Metropolis-Hastings

HTML-код
- Опубликовано: 15 сен 2024
- This video explains the problem with naively running random walk Metropolis on constrained parameters and the remedy of using Metropolis-Hastings in these situations.
This video is part of a lecture course which closely follows the material covered in the book, "A Student's Guide to Bayesian Statistics", published by Sage, which is available to order on Amazon here: www.amazon.co....
For more information on all things Bayesian, have a look at: ben-lambert.co.... The playlist for the lecture course is here: • A Student's Guide to B...


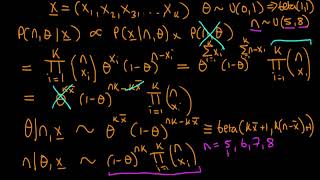






Why does multiplying by jumping distribution fix the issue ?
Great video once again. May I check that:
1. For the final simulation, the shape of the posterior distribution is arbitrary, though in this case, it is only designed to be right-skewed and close to zero, so that the biased-ness of the rejection sampling becomes apparent.
2. I understand that the vanilla metropolis is unbiased, whereas the rejection sampling variant is biased. Though computationally speaking, I have trouble seeing how they are different, since in both cases you reject negative samples of sigma and repeat the sampling process until you get a positive one. In short, following @4.22, I would have coded both approaches the same way.
3. Practically speaking, is it safe to neglect concerns of biasedness of the rejection sampling variant if the distribution is say far from zero and has large positive values?
Thank you for the work you're doing. I am a PhD student in statistics and machine learning who did his undergrad in Engineering, hence I am trying to pick up on graduate level statistics to bridge the gap. I am learning a lot (and quickly) from your resource!
2nd point is exactly my thoughts!
Because in vanilla metropolis, while you do propose a negative value (illegal) of sigma, you can never accept it since the posterior probability of an illegal value is 0. So you anyway propose a new value, until that value is not negative (illegal).
While in the rejection sampling case, if your proposal distribution proposes a negative (illegal) value for sigma, you reject it right away. So, again you propose a new value until it's not negative (illegal).
I honestly don't see a difference!
Did you find an answer to this? Thanks for asking this.
EDIT: I think I get it.
In vanilla metropolis, when you propose a negative (illegal) value of sigma, you then find the posterior probability ratio (which turns out to be 0), so you don't jump to the point and sample the current value. This can lead to a bit of oversampling of values very close to 0 (near illegal regions)
While in rejection sampling, since you immediately reject the negative (illegal) values without calculating the ratio, you don't sample the current value when a negative value of sigma is proposed.
@@abhishekbhatia6092 the difference is that in the 1st case (vanilla) once you reject, you add the last observation again. While in the 2nd case (rejection) you always wait until a valid observation is reached. So if you run this for a 1000 iterations, in the 1st case you will have a lot of repeated values, while in 2nd you won't. But as mentioned, the 2nd will be biased. And in any case both will be less efficient than Hastings.
@@RealMcDudu Can you elaborate what you mean by "once you reject, you add the last observation again"? The vanilla case also keep making new proposals from current parameter value, and only positive proposals won't be automatically rejected. Still it looks the same as the 2nd case, though I know 2nd case was wrong and the proposal is non-symmetric.
@@yuanhu7264 I agree. Don't see any difference between case1 and case2.
@@yuanhu7264 No. In the 1st case you reject the proposal, i.e. you keep the last point, x_(t+1) = x_(t).
Thanks for the video! However, @3:31, I understand the reject sampling is not symmetric, thus inappropriate to use for Metropolis algorithm. But as a matter of fact, wouldn't reject sampling results in the same consequence as method 1, in which the proposal was automatically rejected in the likelihood function? Upon rejection, method 1 makes another proposal, and will be automatically rejected until it is positive. Essentially, because negative values have zero probability in the target density, the proposal from the other direction would never occur. Can anyone clarify this issue? Thanks!
Why does metroppolis also not have the same jumping distribution problem?
Hi,
Thanks for these masterpiece videos. Please in what particular order can one watch your videos? I am very new to Bayesian and it hasn’t been easy for me
Hello Ben awesome video. I wonder if you might be willing to share some of your mathematica notebooks? I am starting to learn mathematica and it would be helpful.
Hi David, thanks for your comment. Yes, that’s what I was thinking of doing. Over the next week or so I’ll try to put them up; either in the caption or on my website. Will let you know when I have done so! Best, Ben
Hey Ben, big fan of your book and both econometrics and bayesian videos. I am also getting started with mathematica and would love if you could share some materials as well! Thanks for putting these out here to help truncate our learning.
Would you mind sharing application in Mathematica? And even if R codes is avaliable?
What the hell is the difference between the first and second proposal for sigma-t-prime in the Metropolis algorithm? Both looked exactly the same.
They are the same. But, in the second one, the proposed value is sampled until it is greater than zero. Then, the sample is rejected/accepted.
This is a fantastic video.
I have just one question: how do I obtain the likelihood and prior?
I am guessing for likelihood you can calculate the product of the probability densities of each data point from N(mean, b_t).
What about the prior?
Worse: What if the data shows a difficult to model distribution?
Hi... what do you mean when you say "kernel"?
more example Ben10