Interesting video showing a single RowGroup... You present well, and clearly have a solid grasp of the Parquet file format. If you're interested in preparing a sequel to your video... ... considering showing a diagram of MULTIPLE row groups, each stored on a different disk in a different node in a cluster, so that a RowGroup represents the "sharding" (splitting across rows in the logical representation of a table) of a logical table and distributing shards-as-RowGroups on DIFFERENT nodes. Then you could explore what happens during a query like "What is average square ft in ZIP Code 60542?" This query can & will be PARALLELIZED into 1 query on each disk where a portion of the larger (logical) table has been stored. What's COOL about parquet is this: - in a ROW-based storage format to get the ZIP from a single record I have to read EACH row, FIND the ZIP field and return it. - therefore in a row-based "shard" containing (say) 10,000 rows across (say) 10 disks (so 1,000 rows per disk) I have to make 10,000 READS across different regions of my disk... VERY INEFFICIENT just to get a SINGLE field (sqft) :-( - in a COLUMN-based storage format I simply have to make 1 single read , starting with where the sqft data begins, and stopping where this field ends. And in a SINGLE read (NOT 1,000) I have ALL the sqft values in that shard representing those rows in my larger (logical) table :-) - MEANWHILE on my other (say 10) disks also containing this (logical) table, there are also only 1 READ per disk, The result? Instead of 10,000 reads across 10 disks just to get 10,000 measely values of sqft to average... ... the parquet format lets me make only 10 reads and get the same 10,000 values :-O Illustrate THIS in your next video ;-) You'll be a hero :-) -Mark in North Aurora IL ...
Hi all , I am searching a way to load the parquet file but not in one go. Want to load in parts . How can i achieve this in Java . Any Implementation reference will be highly appreciated. I have gone through few articles but not up to the mark.
Thanks! Unfortunately dont have the slides anymore. The images used in the slides have been sourced from the official parquet site parquet.apache.org/documentation/latest/
Great talk! I set up a spark-cluster with 2 workers. I save a Dtaframe using partitionBy ("column x") as a parquet format to some path on each worker. The matter is that i am able to save it but if i want to read it back i am getting these errors: - Could not read footer for file file´status ...... - unable to specify Schema ... Any Suggestions?



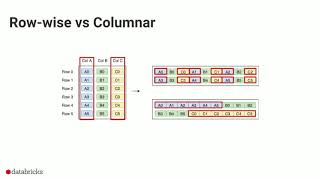






Best explanation of parquet file and columnar file format, I came across so far. Thank you very much
Interesting video showing a single RowGroup...
You present well, and clearly have a solid grasp of the Parquet file format.
If you're interested in preparing a sequel to your video...
... considering showing a diagram of MULTIPLE row groups, each stored on a different disk in a different node in a cluster, so that a RowGroup represents the "sharding" (splitting across rows in the logical representation of a table) of a logical table and distributing shards-as-RowGroups on DIFFERENT nodes.
Then you could explore what happens during a query like "What is average square ft in ZIP Code 60542?"
This query can & will be PARALLELIZED into 1 query on each disk where a portion of the larger (logical) table has been stored.
What's COOL about parquet is this:
- in a ROW-based storage format to get the ZIP from a single record I have to read EACH row, FIND the ZIP field and return it.
- therefore in a row-based "shard" containing (say) 10,000 rows across (say) 10 disks (so 1,000 rows per disk) I have to make 10,000 READS across different regions of my disk... VERY INEFFICIENT just to get a SINGLE field (sqft) :-(
- in a COLUMN-based storage format I simply have to make 1 single read , starting with where the sqft data begins, and stopping where this field ends. And in a SINGLE read (NOT 1,000) I have ALL the sqft values in that shard representing those rows in my larger (logical) table :-)
- MEANWHILE on my other (say 10) disks also containing this (logical) table, there are also only 1 READ per disk,
The result?
Instead of 10,000 reads across 10 disks just to get 10,000 measely values of sqft to average...
... the parquet format lets me make only 10 reads and get the same 10,000 values :-O
Illustrate THIS in your next video ;-)
You'll be a hero :-)
-Mark in North Aurora IL ...
Great overview! Thanks for taking the time to record it!
best explanation of columnar storage format
Nice video but i dont see any row group tuning parameter directly. It is tuned via block.size itself. Is my understanding correct?
Excellent talk!!
Very nice. Brilliant. Thanks.
Hi all , I am searching a way to load the parquet file but not in one go. Want to load in parts . How can i achieve this in Java . Any Implementation reference will be highly appreciated. I have gone through few articles but not up to the mark.
Nice Explanation !!
crazy good videos .... you are godly
Wow..thanks 😀
Good lecture. Play at 1.25x
Awesome talk. Melvin, can you share your slides? via Slideshare or something.
Thanks! Unfortunately dont have the slides anymore. The images used in the slides have been sourced from the official parquet site parquet.apache.org/documentation/latest/
Why the parquet store the data as row layout (row group)? Does it store data as column side by side?
Great talk!
I set up a spark-cluster with 2 workers. I save a Dtaframe using partitionBy ("column x") as a parquet format to some path on each worker. The matter is that i am able to save it but if i want to read it back i am getting these errors: - Could not read footer for file file´status ...... - unable to specify Schema ... Any Suggestions?
What happens if i write a parquet file that has 2 row group??
excellent..
learnt new things
Parquet-tools not working..