Why Transformers Are So Powerful

HTML-код
- Опубликовано: 9 июн 2024
- I find most explanations get lost in the details so i challenged myself to come up with a one sentence description. It's a new kind of layer capable of adapting its connection weights based on input context. This allows one layer to do what would have taken many. I hope this helps you!








finally! this is most succinct description I found about Transformers that actually increased my understanding. thank you for this. can't wait for the longer version.
so so happy to hear this
True, majority of the explanations in the internet are just blabbering same stuff without any insights. Thank you for the effort and simple explanation you provided.
thank you, and yes there is so much garbage out there.
Don't stop. I literally have discovered your channel yesterday and really, really love your style, deep preparation and the energy you're putting into those videos! Thanks!!
So glad you found it! I definitely will be posting more, i'm just slow. I'm thinking of re-editing some of my old stuff to help build momentum for next series...
I can't believe I found this hidden gem of a channel just through typing in "RSA encryption explaination". You're like... perfect for me.
yay welcome to the family, i know it's hard to find my channel as YT isn't friends with it anymore
@@ArtOfTheProblem Use a long list of keywords in your description. It will help.
I didn't know that still worked, I'll try it. If you have other thoughts let me know!@@yahiiia9269
Easy, "more than meets the eye"
😂😂
Whaaaat????! I have watched many hours of videos about transformers, trying desperately to understand how they work, and this is the first video that explained how attention heads are actually dynamic hidden layers that are adjusted on the fly. The other videos made it seem like attention heads are simple score values, but I had no idea that they are in fact large matrices (rivaling the size of static hidden layers) with weights that are adjusted in real-time as each new token is generated! 🤯 Thank you for sharing this huge insight! 🥰
wooo!!! i know i'm so happy to have had this insight and shared it, and it's working for some :)))
@@ArtOfTheProblem❤
thanks!@@traenkler
Yes! Exactly what @VoldiWay said. I too suffered from the same gap in understanding. And @ArtOfTheProblem, you are the 1000 watt epiphany light bulb 💡
woooo!!!@@adamcole918
This is akin to changing my focus while giving feedback to artists. The input gives clues about how advanced they are, which informs what kind of feedback they would find most relevant.
Interesting analogy, it also explain in context learning too
Glad to see you've been posting videos. I'll grab some popcorn for them. :)
welcome back! really just one new video, let me know what you think
Let me know if this insight helps you at all or spurs other ideas. The next video will be the conclusion to my AI series which is currently here: ruclips.net/video/YulgDAaHBKw/видео.html&ab_channel=ArtoftheProblem
do you have a patreon or another efficient way to get a donation? not sure if membership through youtube is efficient (twitch for example takes half of it, and then you ofc still have to tax your half)
thanks for asking I do have one here: www.patreon.com/artoftheproblem@@NoahElRhandour I really appreciate it
Finally. I went through the same hurdles, too. Couldn't grasp the main concept behind Transformers. This video captures the essence of it very successfully. I wonder why no one has expressed it this way before, too.. Thank you very much for your efforts.
appreciate this, I know....i took me a long time. But i think i've seen others start to land on this too...just once in a talk I was watching last week
Often can't intuitively grasp subjects until I watch your videos. I'm eager for your next release.
Took 2 years to finish this one, finally live would love your feedback: ruclips.net/video/OFS90-FX6pg/видео.html
Can’t wait for the new video!
new vid! ruclips.net/video/OFS90-FX6pg/видео.html
I read a lot about tranformers myself and came to the same conclusion. Look forward to see your video.
would love to hear how you were thinking about it.
@@ArtOfTheProblem My mental model was similar to the visualization you had with the musical piece.
But I think the way you look at it is probably better.
Very cool visualization!
Excellent! Very excited for the full video. Always great work man!
thanks nice to hear from you!
I am glad that your back to making content
new vid! ruclips.net/video/OFS90-FX6pg/видео.html
Already watched it 2x man
Glad you’re back.
Just, WOW! Can't wait for the final video!
it's done! ruclips.net/video/OFS90-FX6pg/видео.html
You are having a great skill to explain complex topics with simple words without using advanced graphics.
thank you! i did this one very rough and I'm glad it still works well
@@ArtOfTheProblemI saw may videos on this topic with lot of math and graphics but I don’t pic exact anaswar for my level of understanding but all your videos on deep learning & generative AI gives excellent explanation on complex topics like this. We are greateful for having you on RUclips .
thank you, stay tuned for more!@@signalch1025
Brilliant work sage!
thank you, glad this helped you
So happy to hear from you again :)
I'm amazed I haven't seen this insight before. As you observe, every explainer simply goes down the pre-existing path-of-least-resistance. Would be great if you had a Discord.
thanks! happy to hear this, i don't have a discord but I do stay active in comments
Thank you so much ! Your videos always provide crystal clear explanations.
thanks a full version coming soon
Hey this is a late discovery of this video. I always love your work. (Haven't seen your next video yet) Another way I want to think about transformers based on my limited understanding is that they're just like CNNs (more so than RNNs despite the frequent association between them) but the structures that makes these networks smaller and trainable isn't a *convolution filter* but an *attention head*. Then, just like CNNs, upon passing them through a filter of some sort, they pass these into a smaller fully-connected NN.
great to have you back, let me know what you think of the next video please. And yes your intuition is in the right direction.
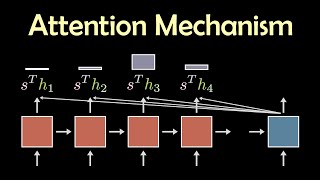
This video demystifies Transformers. It moves beyond explanations that get lost in query, key, value matrices and positional encoding. Instead, we explain that a unique layer adapts its connection weights based on input context. This expands the Transformer's efficiency and prowess.
We Compare this dynamic nature with static layers in traditional networks. And see why Transformers excel at complex tasks with fewer layers.
Get a visual grasp of how mini networks within layers, known as attention heads, act as information filters. They adjust to input and enhance the model's learning capability. [At training time?] This explanation sheds light on what makes Transformers a game-changer in deep learning.
[so it works at training time and inference time - those get confused]
appreciate this!
amazing work!
glad this helped
Adapt its connection weights based on its inputs! Dynamic connection weight!! Now it all is starting to make sense 🙏🙏🙏
yes! was excited when I had this insight and i'm glad it's helpful
Really good summary. For me it first clicked when I saw Karpathy's transformer series. The data "describes itself", resulting in the Keys. Data can also ask for other kinds of data's keys using Queries. And finally Values are simply modified versions of the data. Each head modifies data differently, and learns different ways of summarizing/describing the data. So what we learn during training is this meta-learning process of describing data, literally the "transformers".
thanks for sharing, i'm curious did you find this video after seeing the history one, or was it recommended? i'm just trying to figure out what's happening as i'm finally getting a ton of views
A friend sent me the history video, which struck me by its quality. Then I looked at other videos on your channel. Keep it up! @@ArtOfTheProblem
word of mouth, awesome! welcome to the family
This is the type of explanation i want. I want insight into how and why these mechanisms are able to act in an intelligent way. I eagerly await your longer video.
awesome!
Very interesting. Subscribing to the comments! Also I had to ask GPT4 for some definitions: In the context of Transformer models in machine learning, an "information head" usually refers to a specific part of the model that focuses on capturing some aspect of the data. Think of it like a mini-detector within the model that's good at picking up a certain kind of information, like understanding the meaning of a word in relation to other words.
An "information filter," on the other hand, is a mechanism that decides what information should be passed on and what should be ignored. Imagine it as a sieve that only lets important bits of information flow through, helping the model focus on what really matters for the task it's trying to accomplish.
also GPT4 seems to agree with the insight!
Q:Does it make sense to explain a transformer model as a combination of several smaller models with just one hidden layer (i.e. the attention heads) and a filtering layer that feeds the input in parallel to the many attention heads?
Answer: Yes, that's a reasonable way to simplify the complex architecture of a Transformer model. You could think of each attention head as a mini-model focusing on a specific part of the input data. These attention heads operate in parallel, like multiple workers each doing their own specialized task.
The "filtering layer" you mentioned could be thought of as the mechanism that decides what information is most relevant for each attention head to look at. It essentially prepares the input data so each attention head can do its job more effectively.
After all attention heads have done their work, their outputs are usually combined and passed through additional layers to make the final prediction or interpretation. So, in simple terms, yes, you can describe a Transformer as a combination of several smaller models (attention heads) with a filtering layer that guides them.
interesting, I'm still mulling over this@@belibem
2:18 There’s something profoundly beautiful in that visual of a transformer processing music
AotP uploads are always on time
feels late but glad to hear it :)
I want to quit my career and do something with computers just because your videos make it so amazing.
:) what do you do for a living? I find myself wanting to get away from computers practically speaking, but I do love thinking about them and GPT really was a spark that got me dreaming again....
@@ArtOfTheProblem studied medicine in south america... mostly paperwork in a failing system centering on benefiting clinics and big pharma. computer people could change medical education with their knowledge... it sucks life and money away and its not worth it unless you manage to get into residency which is statistically unlikely here, and even then most specialists say its too much work and little benefit. technology could change that.
Can't wait for the full video
thanks stay tuned
I think the idea of "network that adapts to the input" can be useful to get a good intuition on how attention works, though I don't think that's really the key idea here. I mean, every neural network technically adapts to its input. Intermediate activations change based on the input. Self-attention weighs the linear combination of input embeddings based on... the input. So, as you have argued yourself, they are not so different from a black-box perspective - they just crunch numbers differently, and you could argue they would be functionally equivalent given enough memory and training time (it would be vary fancy to mention universal approximation theorems here, but I'm definitely not qualified to do that).
I would say that, while there are no definitive answers to why transformers actually work and, most importantly, scale so well, IMHO the key insight is that attention is an incredibly effective inductive bias in the architecture - it just makes it more suitable to process sequential data, since it somehow injects in the architecture the concept that "some elements are more important than others, depending on the context". Mind that this is by no means exclusive to transformers, attention was around at least a couple of years prior: this is a nice reconstruction of its history, though you have probably read it already: lilianweng.github.io/posts/2018-06-24-attention/
Regardless of where it comes from, I think this inductive bias of attention is what you refer to as "squishing the network": the architecture effectively has sequence processing built inside of it. I would instead avoid the term "adaptive network" because I would argue that every network is somehow "adaptive".
Having said that, I'm a big fan of your work and I can't wait to see the finished product!
Great comment thanks for sharing. Yes definitely functionally equivalent in theory, and yes every network 'adapts' to input using fixed weights - will think more
I'm focused on the weightings between word pairs being adaptive, which is as you say "a different way of crunching numbers" - when you say adaptive you are talking about 'activations' , right? That makes sense to me, but those adaptive activations are a result of fixed weights and dynamic inputs interacting. what about dynamic and dynamic interactions?
I find your comment "sequence processing built inside of it" interesting, can you say more about this? because in regular fully connected networks you can think of as each layer as a "step in a processing sequence" (networks "learn a program"). I don't see sequential data being key as Transformers (attention) is good at non sequential data too
Also the terms adaptive/dynamic can be misleading because someone may think that the weights of the model are dynamically changing, which is not true. Once the model is trained the weights are static if I get it right.
It's a bit trickier because in transformers they are static (the weights of the QKV matricies) BUT it's designed so that the weighting between word pairs is a result of the interaction between the two matricies they are passing information through - and that result will depend on the words themselves. That's what I mean by adaptive weights. One issue with my analogy is i'm trying to make a very very high level claim about low level details @@belibem
@m-pana
Your vids are fantastic!
thank you! let me know what you'd like to see more of
Thanks! I'm trying to study the field, and it's difficult to try to reach for the essence like you did.
This is a cool explanation.
Took 2 years to finish this one, finally live would love your feedback: ruclips.net/video/OFS90-FX6pg/видео.html
thanks for boiling it down to the essential, which is a sign of great intelligence!
That's the key insight. Intelligence and compression might be the same thing!
Aha! Thank you! My goodness I never got this insgiht despite also reading a ton about these things. And it makes sense: our neural connections are very dynamic, so it's no surprise really that adding dynamism to simulated neural networks would make them "smarter" and more efficient. I hope in the future people figure out how to add even more dynamism, so that these networks can learn properly over time like we do, instead of needing massive training runs that are so very static and expensive (and not personal to a single AI agent's experience).
thrilled this video resonated
🎯 Key Takeaways for quick navigation:
00:00 🤖 Transformers' core insight is self-attention: a network with dynamic connection weights that adapt based on input context.
00:28 💡 Self-attention layers are context-sensitive, making them more efficient at processing information in one layer than traditional networks.
01:10 🧠 Self-attention allows for shorter networks while maintaining efficiency, unlike fully connected networks that are impractical due to excessive parameters.
01:37 🔄 Attention heads within the layers dynamically adjust connections between input words, acting as information filters.
02:32 🎓 Mini networks in the attention heads are learned by the network during training, defining the dynamic interaction of input words.
cool this is an AI right?
Thanks
new vid! ruclips.net/video/OFS90-FX6pg/видео.html
I can't wait for that vidéo to drop i still remember thé vidéo you made about neural networks years ago.
Took 2 years to finish this one, finally live would love your feedback: ruclips.net/video/OFS90-FX6pg/видео.html
Can't wait!
I am so looking foward to the next video!
As you said, for some reason transformer explanations are all so similar...
The worst tutorials are the ones that start with talking about the downsides of RNNs and LSTMs and why transformers fix that. I want to know how the thing works, not why it fixes flaws of other things that I don't fully understand!
Ideally I would love a video with a simple example that one could follow by hand with pen and paper, similar to the explanation by Brandon Rohrer on deep neural networks back in the day: ruclips.net/video/ILsA4nyG7I0/видео.htmlsi=bycRDWN6o0y12ju6 (the first ~ 12 minutes are really original and insightful and what makes that explanation special, the 2nd half is more a standard explanation of backpropagation).
But I fear that it's more difficult to understand the buildup of concepts over multiple layers in a transformer.
I already like the shift in mental models to understand how transformers work.
Can't wait for the next video. :)
Took 2 years to finish this one, finally live would love your feedback: ruclips.net/video/OFS90-FX6pg/видео.html
thanks))
This is what I need. Adaptive Learning
there you go!
would love if you could help share my newest video: ruclips.net/video/5EcQ1IcEMFQ/видео.html
I saw you later video first, so am back-tracking. I wonder if you could think of each Attention Head as a Huffman tree? Where the branches can span a variable length number of time intervals?
HES BACK!!!!!
new vid! ruclips.net/video/OFS90-FX6pg/видео.html
Thx, waiting for new video on transformers, yea
stay tuned!
@@ArtOfTheProblem yea,
Excellent insight! Where can I get the full video of transformer music generation?
Thank you! I'm looking forward to your long video. Btw, do you have a twitter account?
Yes I do twitter.com/Artoftheproblem
you are the GOAT!!!
thank you!
This is a great explanation and also the one that most people who truly understand the architecture ascribe to -- although few explain it that way, curiously. Transformers perform KNN in a latent space -- the difference is that they calculate a latent space specific to your input context, and are able to modify that latent space as new information comes in.
love this
you say that an attention layer can dynamically adapt its weights during run-time (as opposed to training time) ? this is something new to me, as I did not realize that the LLM can be changing its own weights during inference time, and I would love to hear some clear (mathematical if possible) explanation about it. Also, you mention that the attention mechanism is equivalent to transforming an otherwise deep network with many hidden layers to a shallow network with one big hidden layer that can be trained easier? isn't this completely in contrast to the whole deep learning "movement", whereby the deep network usually wins because it can "transform" the otherwise local minima in the search-space into "saddle-points" from which with enough training you can escape? Thank you for your videos.
thanks!
1) It's still "deep" just not "so deep as to be untrainable"
2) the dynamic connections I'm talking about are defined by the Key/Value matricies which interact on a word level at each layer
lmk if you have more Questions
hi there, thanks for the content, btw what is the source of the transformer processing music animation ?!
hey this should be in the description or in the video watermark i found it on twitter
Can you please add more tiers between second and last in your patreon ❤
it's okay, just join the family!
Brilliant. Is the longer video coming out at some point?
it's out! ruclips.net/video/OFS90-FX6pg/видео.html
yes!
glad this helped you!
Bro has police running behind him 😂 🚨🚓
shhhh
Any update on the longer video that this is part of?
I'm actually just finished the script and hope to post in a week or so, sorry for delay! if interested my script is here as i'm looking for notes: docs.google.com/document/d/1s7FNPoKPW9y3EhvzNgexJaEG2pP4Fx_rmI4askoKZPA/edit
What's the source of the music-processing video at 1:57?
I have the source in this new video: ruclips.net/video/OFS90-FX6pg/видео.html
Giant robot movies with bayhem and big 'splosins.
0.40 ... a new kind of layer, which can adapt its connection weights based on the context of the input...
do you like this framing?
It would be useful if you could be more specific about what you mean by "more efficient". "Efficient" in what respect(s)? "More efficient" usually means "doing more (of something X) with the same, or less (, of something else Y). So what are the something X and the something else Y here?
A really non-obvious (to me, at least) thing about attention is why does having multiple attention heads (as all real transformer layers do) do anything more than what one head would do? The answer is that they're all randomly initialized to they have at least the opportunity to all learn separate ways to contribute (in practice, this doesn't work perfectly -- some do the same thing as others, and some contribute little or nothing).
In this case efficient means fewer layers of depth in the network. and ultimately fewer connections.
the attention heads each learn different aspects, it turns out that adding them helps, up until a certain point - this is active research
Correct!!! The genius of transformers isn't even attention. It's the connectivity pattern. The ability to treat data as virtual neurons.
yes! i was originally thinking data creating 'synthetic connections'
@@ArtOfTheProblem It bears considerable resemblance to metric learning in that it is flexible, extensible and retrieval-based. When explaining transformers to others I often consolidate the query-key product to a general relationship I refer to as the "relevance function" of that data point to this data point in the current context. One term fewer and it simplifies the discussion into something we already think about natively
yes, perfect@@sethstewart1103
SHA-256 can compress ngrams of any size into a 64 chars.
Is it annoying when progress is happening so quickly that you (presumably) have to keep updating your voiceover? I understand you focus on the fundamentals and those are the same, but even just references to the current chatGPT version etc gotta be updated right?
tell me about it, I started my next video (on how networks process sequential data) before chatGPT even came out, threw me for a looooong loop. but at this point I'm ready to make the next video and hit on all the high level Ideas which will stay relevant regardless of GPT 5 etc.. I'm excited about it.
this is it. :))))))
Me: those are AND logics,
but the real power isn't the transformer, it's the embeddings, AND I don't want to spill the bean just yet.
say more!
"input self similarity pre learned"@@ArtOfTheProblem
interesting, so are you saying that the real power isn't the transformer but the importance of embeddings and how they might already encapsulate some notion of 'input self similarity'. @@NeoShameMan
They prevent the network from learning an arbitrarily sparse input, ie the data is self sorted, the self similarity encode the distribution bias that define the inherent semantic of the input. LLM are "special" in machine learning because the input distribution and the output distribution is the same.
You can basically bog down neural network at large into two main function, sorting input data together, then tagging them with class.
The transformer is merely a clever acceleration structure, but if you look at the evolution of power of neural network, limiting the input field (attention mechanism) as been a way to accelerate learning and increase power.
Most big LLM are very sparse with neuron only reacting to specific Ngram (aka bag of word), I encourage you to look at how chatbot using chatscript are program too (suzette and rosette).
The reason is that you tokenized the input allowing better composition (ie higher level token), reproducing an adhoc parsing tree. This pose the question, what limit a dag impose on that structure.
LLm goes one step beyond and dissociate teh learning of the input (embedding training) and the output token generation) ie it's virtually deeper than the "physical" model because really it's two model chained together. @@ArtOfTheProblem
But I would go much deeper, I would ask you, what function are the neuron ACTUALLY are doing, I don't mean logistic regression and the kind, I mean *concretely*, try to separate each mechanism of the neuron (beyond the bs brain analogy or obscure math) and question yourself what do they do (the mul, the add, the bias, the activation).
After all the math is merely the same as groceries store ticket you look at to see if you got over budget or not...
IMHO LLM will go the way of NeRF vs Gaussian splatting ... YAGNNNI! (You Aren't Going to Need Neural Network for Intelligence)
"Transformers is a series of science fiction action films based on the Transformers franchise of the 1980s." (wikipedia)
calling a new technology by the same name is more idiotic than the film/series itself. 🤦🏼♂
it is more efficient to name it XxX btw... :(
"A transformer is a deep learning architecture that relies on the parallel multi-head attention mechanism. The modern transformer was proposed in the 2017 paper titled 'Attention Is All You Need' by Ashish Vaswani et al., Google Brain team." (Wikipedia)
Not being able to add "AI" to your search in order to find it, says more about your search skills than anything.
imagine having a brain that understands what he is saying..lol..
ok, but... can you explain in one sentence what the fuck Transformers is so I can google it?
Energon makes them powerful.
Thanks
WOW thank you so much for this. I'd love to know if you were struggling with this concept? what else are you looking for help with. right now i'm working on an RL video