25:50 the sentence "Errors due to further back time steps have smaller and smaller gradients because they have to pass through this huge chain rule in order to be counted in as part of the loss." clarified me about how that long term dependency dissappears in RNN. This implies that it is because that the affect of the change of the weight(gradient) in account of the first words to our loss is now just skinny numbers. Those numbers actually have no saying at all in the overall gradient change which means our model won't be shaping to minimize this loss accourding to them(first words). Thanks.
Good video describing the LSTMs. The only part I did not like about the video is the description of Morkov model at around 11:00 minutes. Morkov models can capture a richer state than just the previous word. Also the lecturer mentioned that Markov models assume that each state depends on the previous state which is incorrect. In Markov models at state s[n] is not independent from s[n-2]. But it is conditionally independent from s[n-2]. Independence of conditional independents has a profoundly different interpretation in statistics and probability theory as well as machine learning.
At 26:37 Wouldn't this affect all the layers not just the ones closer to the output layer, since we're taking the sum of the gradients of all the previous cell states? So wouldn't every node change by the same amount when we update our weights?
A bit strange... "LSTM has a bit more parameters, than simple RNN which has W matrix" -> vanilla LSTM'97 (also true for many other lstms) has only W (+bias) [which often involved all 4 parts in big one] >> but it also passes internal state (c+h), but it's not so crucial to my mind
Hii How to handle persistent model problem. While doing time series analysis i get the output which seems to be one time step ahead of the actual series. How to rectify this problem?? This thing i am getting with several ML, DL, and as well as with statistical algos. Please do reply??
at 25:14, if that the derivatives of tanh and sigmoid most often are < 1 explains gradient vanishing, what about gradient explosion, why would that happen? I am trying to understand this paper better, arxiv.org/abs/1211.5063
At 43:31 the line that has sess.run(optimizer, feed_dict={x: inputs, y: lables}) what specific values should be given for inputs and labels so that I can run the session??
inputs and labels would both be tensors that you would load somewhere in your code. Eg: Say you have an 10 images (each with a 32x32x3 size)), your input to the network at a given instant would be an array of 32x32x3 = 3072 pixels. Your label for this input would be the class of the output in a vector form. Say all the 10 images were either dogs, cats or rabbits, you have 3 classes. For a given image input of 3072 pixels, if your class is cat, your labels vector would be [0 1 0]. For another 3072 input pixels of a rabbit, the label would be [0 0 1] and so on. So once you have constructed an input tensor with the size 10x3072 and output with the size 10x3, you would feed_dict them to optimize the parameters. Hope this helps!
Anyone can explain me mathematical explanation of differentiating the functions of lstm plssss! I wanna know how the backprop works. I need it for my math school project! Plssss helllpp!!
Good video, though I feel like it was more "LSTMs and Tensorflow" than "LSTMs in Tensorflow." The lab looks looks like it fills in the rest: github.com/nicholaslocascio/bcs-lstm/blob/master/Lab.ipynb




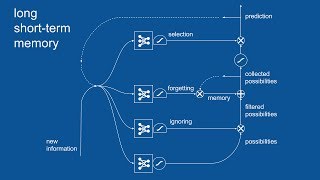





I would give 10 thumbs-up for this clarity and coherence presentation!
I would give 10 thumbs-up for this clarity and coherence comment!
Excellent Lecture on RNN and LSTM, Thanks Harini and Nicholas.
25:50 the sentence "Errors due to further back time steps have smaller and smaller gradients because they have to pass through this huge chain rule in order to be counted in as part of the loss." clarified me about how that long term dependency dissappears in RNN. This implies that it is because that the affect of the change of the weight(gradient) in account of the first words to our loss is now just skinny numbers. Those numbers actually have no saying at all in the overall gradient change which means our model won't be shaping to minimize this loss accourding to them(first words). Thanks.
Good video describing the LSTMs. The only part I did not like about the video is the description of Morkov model at around 11:00 minutes. Morkov models can capture a richer state than just the previous word. Also the lecturer mentioned that Markov models assume that each state depends on the previous state which is incorrect. In Markov models at state s[n] is not independent from s[n-2]. But it is conditionally independent from s[n-2]. Independence of conditional independents has a profoundly different interpretation in statistics and probability theory as well as machine learning.
At 26:37 Wouldn't this affect all the layers not just the ones closer to the output layer, since we're taking the sum of the gradients of all the previous cell states? So wouldn't every node change by the same amount when we update our weights?
Very good video, both general and professional, which helps me clarify important concepts in cs224n.
Audio stuttering ruined a great presentation :/ You should've used LSTM to fill in for it haha
Nitin Issac Joy 😂 😂
Hahaha - My exact thought!
i really was pretty confused how to start with LSTM,, but seriously ur presentation made me supereasy #all stars for harini
39:10 that's my first time hearing numpy pronounced as 'num-pee'
And it was like nails on a chalkboard.
😂
hahahaha here in Colombia all the people say num-pee
I've always called it num-pee.. it feels easier to import num-pee as en-pee
Kind of good explanation but I think in 13:31 should be s1 = tanh(Wx1 + Us0)
A bit strange... "LSTM has a bit more parameters, than simple RNN which has W matrix"
-> vanilla LSTM'97 (also true for many other lstms) has only W (+bias) [which often involved all 4 parts in big one]
>> but it also passes internal state (c+h), but it's not so crucial to my mind
Hii
How to handle persistent model problem. While doing time series analysis i get the output which seems to be one time step ahead of the actual series. How to rectify this problem?? This thing i am getting with several ML, DL, and as well as with statistical algos. Please do reply??
where is the link for the opensource software package ?
As an amature in this field 19:42 was helpful af
25:27 is the derivative right?
Very nice presentation, explained complex things very nicely by Harini !!!
at 25:14, if that the derivatives of tanh and sigmoid most often are < 1 explains gradient vanishing, what about gradient explosion, why would that happen? I am trying to understand this paper better, arxiv.org/abs/1211.5063
At 43:31 the line that has sess.run(optimizer, feed_dict={x: inputs, y: lables}) what specific values should be given for inputs and labels so that I can run the session??
inputs and labels would both be tensors that you would load somewhere in your code. Eg: Say you have an 10 images (each with a 32x32x3 size)), your input to the network at a given instant would be an array of 32x32x3 = 3072 pixels. Your label for this input would be the class of the output in a vector form. Say all the 10 images were either dogs, cats or rabbits, you have 3 classes. For a given image input of 3072 pixels, if your class is cat, your labels vector would be [0 1 0]. For another 3072 input pixels of a rabbit, the label would be [0 0 1] and so on. So once you have constructed an input tensor with the size 10x3072 and output with the size 10x3, you would feed_dict them to optimize the parameters. Hope this helps!
Fantastic Presentation!
The tensorflow is too old for the current tensorflow version.
Wow, that's what I needed explanation via example.
at minute 25 there is an error in the definition of dsn/ds(n-1)?
Where is the continuation?
Harini had a hard time explaining the LSTM architecture. I would recommend to use simple examples to walkthrough the LSTM execution.
did someone go though the tutorial? i need some help to add tensorboard summaries to see what's happening.
One more... -> Speech Apr 26, 2017 >> but you show old Tensorflow API (before 1.0)
hahah ... yeah man, kinda like your implying that MIT quality is just based on propaganda. Like Harvard echonomists.
how's that an issue? version migration is a commitment, and quite often doesn't affect the quality of the outcome.
Nibs Aardvark It can be an issue if people try to code that way with a newer API since 1.0 changed it.
Thank you Harini that was a great presentation :)
So what should we understand from S2=tanh(wx+Us1) how to find U? or is it given already? or we need to initialize U as well ?
just like w, we would need to initialize U as well...as the model trains, it will optimize both w and U
Awesome presentation. Can I look forward to a presentation on ConvolutionalLSTM any time soon ? Anyways keep posting more awesome content.
dsn/ds(n-1) should be U*f'(US(n-1)+WnXn)
Anyone can explain me mathematical explanation of differentiating the functions of lstm plssss! I wanna know how the backprop works. I need it for my math school project! Plssss helllpp!!
Thanks for the wonderful presentation. Nicely explained. Is the slide done in Latex? Can I get the latex code? TIA
I think this was done on Google Slides
Thank you for the nice presentation. Can I get the slides?
introtodeeplearning.com/
wow nice
thanks
This is amazing helpful. Thanks
very helpful and clear
This is a great explaination! Thank you so much!
One of the best introductions I have found! BTW: Here is the link to the LSTM Tensorflow tutorial: github.com/nicholaslocascio/bcs-lstm
The tutorial is greate
Great talk, thanks.
10 points to gryffindor
Great talk
Excellent
Thanks!
vibrant uptalker
Good video, though I feel like it was more "LSTMs and Tensorflow" than "LSTMs in Tensorflow." The lab looks looks like it fills in the rest: github.com/nicholaslocascio/bcs-lstm/blob/master/Lab.ipynb
40:00
I would marry her.
the guy crying about equations....geez