R d. EA dc. Dạ ; Nc N J mẹ N mhh H Xem hs Mh H H H Mh dg Hs J mh mhsjmaheuri đi Mm dj jd : j 在一起了的感觉真的很开心了😃 在 你的人会越来越努力工作努力 是啊 这么d恍恍惚惚是₫( hhdhsh是。👌jz 好多好多 在h h 👌
R d. EA dc. Dạ ; Nc N J mẹ N mhh H Xem hs Mh H H H Mh dg Hs J mh mhsjmaheuri đi Mm dj jd : j 在一起了的感觉真的很开心了😃 在 你的人会越来越努力工作努力 是啊 这么d恍恍惚惚是₫( hhdhsh是。👌jz 好多好多 在h h 👌
Hi, . One question on calculation of tfidf here.. As per the coded formula uh r taking documents which have > 0 occurance. But it should be all the documents right? Is that correct?
@deepak singh - If I understand your question correctly the IDF calculation has the following: corpus.size == the total number of documents doc.count == the number of documents containing the term HTH, Dave
Hi Dave, thanks for your video! learned a lot today. Unfortunately, I'm not blessed with the number of documents you have, in fact, I only have one document to analyze! Therefore, using your log(N/count(t)) would not be rational because a lot of them will hit the score 0. What do I do? Bet on domain knowledge and manually flag certain terms as stopwords?
Hi Dave, First of all i'd like to say your videos are great, simple to digest and follow. So thank you for that! I'm occuring an odd error, stating: 'Error: cannot allocate vector of size 45 Kb' while running the TF function. Would you have any insight of solving the problem? I'd be very greatful! Regards.
Hello. I am just wondering to calculate tf.idf and your video looks great. However, if you could help me understand that I want dictionary specific terms to find from corpus of 500 annual reports and then calculating tf.idf. Is it possible to do it.? In addition, I want identity of annual reports rather mixing it into only one document.
Hi guys from Data Science Dojo. Please, in my case I have just one document. So, dont I need to implement the TF-IDF method? Or, thinking like the documents are the number of respondents that I had in my csv file. Which one may I follow?
Thanks. A good explanatory video on text mining with R was missing on youtube. I have followed your other videos on youtube and found them helpful. One query. Quanteda has inbuilt functions for calculating TF IDF. Any specific reason why you wrote the code yourself?
@Jayl - That is output illustrating that your doSNOW cluster had connections that were not properly closed. It’s nothing to worry about in particular, but it is best practice to ensure that a call to the stopCluster() function is called every time your spin up a doSNOW() cluster. HTH, Dave
Probably this is my first youtube video comment, because i couldn't resist myself appreciating you for this wonderful video. Thank you and kudos to you for such a wonderful explanation. :D
Hi Dave, I am experiencing this problem and I cannot create the matrix needed: Error in asMethod(object) : Cholmod error 'problem too large' at file ../Core/cholmod_dense.c, line 105
I have a bunch of Text files in my folder . And I want answers from all those text files. This should happen like me coding on R . Like when I type some question in R for example what is earth . I need answers extrcated from all those in sentences.
Hi, I am following your tutorial from the start and trying to build model for my problem that includes more than 2 class labels. I tried with the bag of words model like in your fourth tutorial with random forest, it is giving maximum of about 40% of accuracy. Any advice so that i can improve my model accuracy?
@Prateek Argarwal - Without knowing more about your scenario, data, etc. I can only provide advice in the most general sense. Here's what I can suggest: 1 - Try out various types and combination of n-grams. 2 - Try out using both TF-IDF and not TF-IDF. 3 - Try both with and without SVD/LSA. 4 - Try various amounts of singular vectors for SVD/LSA. 5 - Try out various algorithms (e.g., SVMs). NOTE - The above assume continuing with the bag of words model. However, it is possible that this alone might not be enough for your data. For example, you may require more advanced techniques like chunking to create more powerful features. HTH, Dave
Thanks Dave .....basically I am trying to classify the tickets based on user textual complaints. I tried different algos, Random forest is giving the maximum accuracy of 40%.
@Prateek Agarawal - Always keep in mind that you may not have enough signal in your data to build an effective predictive model. I'm not saying that this is true in your particular case, but it is something to keep in mind. For example, the textual complaints might not be enough. You may also need additional data from the tickets (e.g., customer-related data) as well. HTH, Dave
I am having memory issues with 8 GB of memory. Is that to be expected? (It is on a work machine... unsure if I can request more memory) Is there a file or two that I could eliminate to continue the work?
Dear Dave, I really love your tutorials. Thank you very much for all your effort in making these videos and sharing your insights and experience in data science. Besides the Titanic and these text analytics tutorials, do you have any others? I want to check them all out :). Also, I want to ask TF (text frequency) you mentioned in this tutorial is the count of a term over the total number of terms in ONE document or ALL documents in a matrix/ data.frame. Besides, why don't we use 'scale' to normalize our data?
Hi Dave. I'm trying to use this approach but instead of training the model to predict text that results in ham or spam, I'm trying to predict which text leads to better email open rates. I have split my corpus into quartiles ranked by open rate and am training the model against these quartiles. Is this a valid adaptation of your approach outlined in this video series?
@Gareth Lloyd - If I understand your scenario correctly, then yes! The main change will be that instead of a binary classification problem you would have a multi-class problem (i.e., 4 classes with one class for each quartile). The mighty random forest can handle multi-class problems like this just fine. Happy data sleuthing! HTH, Dave
Dear Dave. First of all, thank you for the great introductory course! I've worked through the first 5 videos of this course on the spam dataset, and in parallel I am running the code on my dataset which is slightly larger. In particular I have about 1,6 mln observations each one of them containing just about the same amount of text as in the spam observations. When I created my train.tokens.dfm, I got a large dfm object of 200 bln elements, 420 mb. Then I proceeded to the next step to create a matrix, here is when I encounter memory problems. I've tried (as per your instruction) train.tokens.matrix = as.matrix(train.tokens.dfm) or train.tokens.df = cbind(Label = train$Label, as.data.frame(train.tokens.dfm)) both of these function return the following mistake: Cholmod error 'problem too large' at file ../Core/cholmod_dense.c, line 105 I can imagine what size the matrix must be created with these formulas, but I really do want to use tokenization in my approach. Is there any way around it? Thank you in advance! P.S. I'm running a Macbook Pro core i7, 16 GB RAM P.S.S. Your caret xgboost tutorial is awesome!
update: after checking the dimensions of this dfm here's what I've got > dim(train.tokens.dfm) [1] 1482535 138945 where 1 482 535 is the number of observations and 138 945 is the number of features
@@Fealivren The code (found here: stackoverflow.com/questions/10917532/memory-allocation-error-cannot-allocate-vector-of-size-75-1-mb) to increase storage capacity solved this error for me









Good teaching, so far thanks sir!
Thanks Dave. Really appreciate your style of teaching. Very helpful.
@Avishek Kumar - Thank you for the compliment, greatly appreciated!
All of these videos, all of this playlist has helped me into my thesis. Thanks a lot!
R d. EA dc. Dạ ;
Nc
N
J mẹ
N mhh
H
Xem hs
Mh
H
H
H
Mh dg
Hs
J mh mhsjmaheuri đi
Mm
dj
jd
: j
在一起了的感觉真的很开心了😃
在
你的人会越来越努力工作努力
是啊
这么d恍恍惚惚是₫( hhdhsh是。👌jz
好多好多
在h
h
👌
R d. EA dc. Dạ ;
Nc
N
J mẹ
N mhh
H
Xem hs
Mh
H
H
H
Mh dg
Hs
J mh mhsjmaheuri đi
Mm
dj
jd
: j
在一起了的感觉真的很开心了😃
在
你的人会越来越努力工作努力
是啊
这么d恍恍惚惚是₫( hhdhsh是。👌jz
好多好多
在h
h
👌
Thanks for your contribution to expand the data science knowledge!
Or simply you can use weightTfIdf fom tm package !!
Hi,
. One question on calculation of tfidf here..
As per the coded formula uh r taking documents which have > 0 occurance.
But it should be all the documents right?
Is that correct?
@deepak singh - If I understand your question correctly the IDF calculation has the following:
corpus.size == the total number of documents
doc.count == the number of documents containing the term
HTH,
Dave
Hi Dave, thanks for your video! learned a lot today.
Unfortunately, I'm not blessed with the number of documents you have, in fact, I only have one document to analyze! Therefore, using your log(N/count(t)) would not be rational because a lot of them will hit the score 0. What do I do? Bet on domain knowledge and manually flag certain terms as stopwords?
U r a great teacher! I will follow ur each and every video from now on. Thank you so much. More power to you. Regards
@Bhupendra Kumar - You are too kind. Glad you found the videos useful!
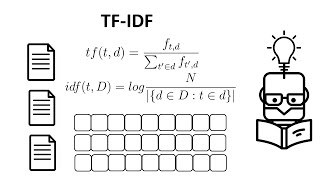
what does "Text" represent?
Hello Maryam, the text represents 'term frequency-inverse document frequency'.
Thanks a lot. Learned a lot today.
Hi Dave,
First of all i'd like to say your videos are great, simple to digest and follow. So thank you for that!
I'm occuring an odd error, stating: 'Error: cannot allocate vector of size 45 Kb' while running the TF function.
Would you have any insight of solving the problem? I'd be very greatful! Regards.
I got same problem. Have you solved?
Hello. I am just wondering to calculate tf.idf and your video looks great. However, if you could help me understand that I want dictionary specific terms to find from corpus of 500 annual reports and then calculating tf.idf. Is it possible to do it.? In addition, I want identity of annual reports rather mixing it into only one document.
Hi guys from Data Science Dojo. Please, in my case I have just one document. So, dont I need to implement the TF-IDF method? Or, thinking like the documents are the number of respondents that I had in my csv file. Which one may I follow?
Thanks. A good explanatory video on text mining with R was missing on youtube. I have followed your other videos on youtube and found them helpful.
One query. Quanteda has inbuilt functions for calculating TF IDF. Any specific reason why you wrote the code yourself?
He explained it in the video because it was easier for viewers to understand how the TF-IDF works.
Should I be concerned with this results when I run my model:
1: closing unused connection 7 (
@Jayl - That is output illustrating that your doSNOW cluster had connections that were not properly closed. It’s nothing to worry about in particular, but it is best practice to ensure that a call to the stopCluster() function is called every time your spin up a doSNOW() cluster.
HTH,
Dave
Probably this is my first youtube video comment, because i couldn't resist myself appreciating you for this wonderful video. Thank you and kudos to you for such a wonderful explanation. :D
@sidhanta maharana - Glad you liked the video!
Dave
Thanks for your videos! Learned a lot!
Hi Dave, I am experiencing this problem and I cannot create the matrix needed: Error in asMethod(object) :
Cholmod error 'problem too large' at file ../Core/cholmod_dense.c, line 105
I have a bunch of Text files in my folder . And I want answers from all those text files. This should happen like me coding on R . Like when I type some question in R for example what is earth . I need answers extrcated from all those in sentences.
Hi, I am following your tutorial from the start and trying to build model for my problem that includes more than 2 class labels. I tried with the bag of words model like in your fourth tutorial with random forest, it is giving maximum of about 40% of accuracy. Any advice so that i can improve my model accuracy?
@Prateek Argarwal - Without knowing more about your scenario, data, etc. I can only provide advice in the most general sense. Here's what I can suggest:
1 - Try out various types and combination of n-grams.
2 - Try out using both TF-IDF and not TF-IDF.
3 - Try both with and without SVD/LSA.
4 - Try various amounts of singular vectors for SVD/LSA.
5 - Try out various algorithms (e.g., SVMs).
NOTE - The above assume continuing with the bag of words model. However, it is possible that this alone might not be enough for your data. For example, you may require more advanced techniques like chunking to create more powerful features.
HTH,
Dave
Thanks Dave .....basically I am trying to classify the tickets based on user textual complaints. I tried different algos, Random forest is giving the maximum accuracy of 40%.
@Prateek Agarawal - Always keep in mind that you may not have enough signal in your data to build an effective predictive model. I'm not saying that this is true in your particular case, but it is something to keep in mind. For example, the textual complaints might not be enough. You may also need additional data from the tickets (e.g., customer-related data) as well.
HTH,
Dave
Dave, love your lecturing!
I am having memory issues with 8 GB of memory. Is that to be expected? (It is on a work machine... unsure if I can request more memory) Is there a file or two that I could eliminate to continue the work?
Dear Dave, I really love your tutorials. Thank you very much for all your effort in making these videos and sharing your insights and experience in data science. Besides the Titanic and these text analytics tutorials, do you have any others? I want to check them all out :). Also, I want to ask TF (text frequency) you mentioned in this tutorial is the count of a term over the total number of terms in ONE document or ALL documents in a matrix/ data.frame. Besides, why don't we use 'scale' to normalize our data?
Hi Dave. I'm trying to use this approach but instead of training the model to predict text that results in ham or spam, I'm trying to predict which text leads to better email open rates. I have split my corpus into quartiles ranked by open rate and am training the model against these quartiles. Is this a valid adaptation of your approach outlined in this video series?
Great thanks for your help. That's exactly how I've set it up; now let's see if it's accurate enough!
Hi Gareth, I am pretty new to this world. it would be very kind of u , if you can share your work. so that I can compare and work my way out.
@Gareth Lloyd - If I understand your scenario correctly, then yes! The main change will be that instead of a binary classification problem you would have a multi-class problem (i.e., 4 classes with one class for each quartile). The mighty random forest can handle multi-class problems like this just fine. Happy data sleuthing!
HTH,
Dave
hey can you help me?
when i run this code
train.tokens.tfidf
What's your corpus' size in disk? O_O
Dear Dave.
First of all, thank you for the great introductory course!
I've worked through the first 5 videos of this course on the spam dataset, and in parallel I am running the code on my dataset which is slightly larger. In particular I have about 1,6 mln observations each one of them containing just about the same amount of text as in the spam observations.
When I created my train.tokens.dfm, I got a large dfm object of 200 bln elements, 420 mb.
Then I proceeded to the next step to create a matrix, here is when I encounter memory problems.
I've tried (as per your instruction)
train.tokens.matrix = as.matrix(train.tokens.dfm)
or
train.tokens.df = cbind(Label = train$Label, as.data.frame(train.tokens.dfm))
both of these function return the following mistake:
Cholmod error 'problem too large' at file ../Core/cholmod_dense.c, line 105
I can imagine what size the matrix must be created with these formulas, but I really do want to use tokenization in my approach.
Is there any way around it?
Thank you in advance!
P.S. I'm running a Macbook Pro core i7, 16 GB RAM
P.S.S. Your caret xgboost tutorial is awesome!
update: after checking the dimensions of this dfm here's what I've got
> dim(train.tokens.dfm)
[1] 1482535 138945
where 1 482 535 is the number of observations and 138 945 is the number of features
Really Helpful Videos
but when run this line of code it gives me an error:
> train.tokens.df
Hello Hussain. I've just got an exact same error. Do You remember if you had solved this issue?
@@Fealivren The code (found here: stackoverflow.com/questions/10917532/memory-allocation-error-cannot-allocate-vector-of-size-75-1-mb) to increase storage capacity solved this error for me
Loved all your videos. I highly recommend these videos to any beginners.
Glad you liked it, stay tuned with us for more tutorials.
This is awesome.... thanks
Thanks yet again!