It's funny that this video (lec 7) has vastly fewer views than both lecture 6 and 8. But if the title of this video was PCA instead of Eckart-Young it would easily be the most viewed video in the series. That's why kids, do the entire course instead of just watching 15 minutes of popular concepts.
That's the exact same thing I think about. I just followed up on the sequence of videos, and I surprisingly notice that this video is about PCA, which is closely connected to previous videos. But viewing previous videos makes the understanding of PCA far deeper!
Gil 3:30. Eckart & Young in 1936 were both at The University of Chicago. The paper was published in the (relatively new?) journal Psychometrica. Ekhart had already worked in the foundations of QM with some of the founders. And went on to work in Fermi's section on the Manhattan Project. If I recall correctly, Eckart married the widow of von Neumann. And ended up at UCSD. He was very renowned in applied physics including oceanographicy/ geophysics. Mr Gale Young was a grad student at Chicago. He also had a successful career taking his Master's from Chicago to positions in acedemia & US nuclear power industry.
In the least-squares vs. PCA discussion that starts at 37:44, he's comparing minimizing sum of squares of vertical distances to minimizing sum of squares of squares of perpendicular distances. However, each vertical error is related to each perpendicular error by the same multiplicative constant (cosine of the angle made by the estimated line), so in a way, minimizing one is tantamount to minimizing the other. Where the two methods do seem to differ is that least squares allows for an intercept term, while the PCA line goes through the origin. However, when we look at the estimate of the intercept term ( b_0 = mean(y) - b_hat*mean(x) ), least squares appears to be performing a de-meaning similar to the first step in PCA. In summary, I think we would need a more thorough discussion than we see in the video in order to conclude that least squares and the first principal component of PCA are different.
Professor Strang thank you for great lecture that involves Norms, Ranks and Least Squares. All three topics are very important for solid linear algebra development.
44:40 - No, it's not making the mean zero that creates the need to use N-1 in the denominator. That's done because you are estimating population mean via sample mean, and because of that you will underestimate the population variance. It turns out that N-1 instead of N is an exact correction, but it's not hard to see that you need to do *something* to push your estimate up a bit.
Well, indeed I guess both are saying more or less the same thing. This is called Bessel’s correction. I prefer to think that dividing by N-1 yields an unbiased estimator, so that on average the sample cov matrix is the same as the cov matrix from the pdf.
@@philippe177 The best explanation I've found is in a book called "Data Mining: The Textbook" by Charu Aggarwal. The tl;dr. Imagine you have a bunch of data points in Rn, and you just list them as rows in a matrix. First assume the "center of mass" (mean value of rows) is 0. Then PCA = SVD. The biggest eigenvalue/eigenvector points in the direction of largest variance, and so on for the second, third, fourth, etc eigenthings. In the case where center of mass is not zero, SVD gives you the same data as PCA, it just takes into account that the center of mass has moved.
at around 37:15 when the Sir is talking about difference in Least Squares and PCA. I think minimization will lead to same solution as perpendicular length is proportional to other line. Hypotenuse * sin(theta), where theta is the angle between vertical line and the line of least squares which must be fixed for a particular plane(line). I could not understand where I am going wrong.
Very nice doubt bro. The catch is in the theta. Let us assume that first you used least squares and found out a line such that error is minimum and it is equals to E. Then as you said the error in case of PCA should be sin(theta) * E , here change in theta will have a direct effect to minimize error of PCA since it is in the product. So minimizing just E will not work, as you should minimize the product, and sin(theta) is also there. I hope you got i want to say.
Good lecture, but I feel it only just starts getting into the heart of PCA before it ends. I don't see a continuation of the the discussion in subsequent lectures, so I'm wondering if I'm missing something.
I always thought the N-1 was related to the fact that the variance of a single object is undefined (or at least nonsensical), so the N-1 ensures this is reflected in the maths? As well as something related to the unbiasedness of the estimator etc.
This is called Bessel’s correction. I prefer to think that dividing by N-1 yields an unbiased estimator, so that on average the sample cov matrix is the same as the cov matrix from the pdf.
Most of the material is in the textbook. There are some sample chapters available from the textbook, see the Syllabus for more information at: ocw.mit.edu/18-065S18.



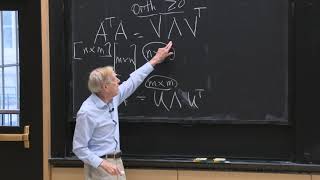






What a wonderful lecture! I wish Prof. Gilbert a very long life.
I love Prof. Gilbert Strang, he is a dedicated man to teach mathematics. Please receive a huge hug on my behalf.
10 years ago I took OCW for the first time and I am still taking it. Thank you professor Gilbert Strang.
It's funny that this video (lec 7) has vastly fewer views than both lecture 6 and 8. But if the title of this video was PCA instead of Eckart-Young it would easily be the most viewed video in the series.
That's why kids, do the entire course instead of just watching 15 minutes of popular concepts.
well said
He has not explained anything about PCA in this lecture. He barely started out in the end and it wrapped up.
That's the exact same thing I think about. I just followed up on the sequence of videos, and I surprisingly notice that this video is about PCA, which is closely connected to previous videos. But viewing previous videos makes the understanding of PCA far deeper!
Really deep lectures, I learn something new every time I watch them again and again. These lectures are gold.
Gil 3:30.
Eckart & Young in 1936 were both at The University of Chicago. The paper was published in the (relatively new?) journal Psychometrica. Ekhart had already worked in the foundations of QM with some of the founders. And went on to work in Fermi's section on the Manhattan Project. If I recall correctly, Eckart married the widow of von Neumann. And ended up at UCSD. He was very renowned in applied physics including oceanographicy/ geophysics.
Mr Gale Young was a grad student at Chicago. He also had a successful career taking his Master's from Chicago to positions in acedemia & US nuclear power industry.
Thank you for being who you are and touching our lives!!! I am VERY VERY grateful.
Fixed audio sync problem in the first minute of the video.
You guys are the best!!
Thank you !
Gil has been my math professor for the last 12 years. These online courses are so amazing.
you have changed my life Dr. Strang!
His passion, knowledge and unique style. He's such a treasure. An amazing professor and wonderful mathematician.
In the least-squares vs. PCA discussion that starts at 37:44, he's comparing minimizing sum of squares of vertical distances to minimizing sum of squares of squares of perpendicular distances. However, each vertical error is related to each perpendicular error by the same multiplicative constant (cosine of the angle made by the estimated line), so in a way, minimizing one is tantamount to minimizing the other. Where the two methods do seem to differ is that least squares allows for an intercept term, while the PCA line goes through the origin. However, when we look at the estimate of the intercept term ( b_0 = mean(y) - b_hat*mean(x) ), least squares appears to be performing a de-meaning similar to the first step in PCA. In summary, I think we would need a more thorough discussion than we see in the video in order to conclude that least squares and the first principal component of PCA are different.
33:54 "Oh, that was a brilliant notation!" LOL!.
Professor Strang thank you for great lecture that involves Norms, Ranks and Least Squares. All three topics are very important for solid linear algebra development.
44:40 - No, it's not making the mean zero that creates the need to use N-1 in the denominator. That's done because you are estimating population mean via sample mean, and because of that you will underestimate the population variance. It turns out that N-1 instead of N is an exact correction, but it's not hard to see that you need to do *something* to push your estimate up a bit.
Well, indeed I guess both are saying more or less the same thing. This is called Bessel’s correction. I prefer to think that dividing by N-1 yields an unbiased estimator, so that on average the sample cov matrix is the same as the cov matrix from the pdf.
a privilege to take part in such a distilled lecture. no confusion at all.
Protect this man at all cost! Now we know, what an angel looks like!
Most interesting linear algebra lecture ever!! It's very easy to understand even for us chemistry students
27:00 matirx A multiply orthogonal matrix, the norm of A doesn’t change
Anyone else thinks he talks with the same passion for math, as Walter White does for Chemistry? Love this guy.
lol
is it my computer or is the sound level a bit low?
Where is the follow-up lecture on PCA it seems to be missing from the following lectures?
Did you find it where. I am dying to find it.
@@philippe177 The best explanation I've found is in a book called "Data Mining: The Textbook" by Charu Aggarwal. The tl;dr. Imagine you have a bunch of data points in Rn, and you just list them as rows in a matrix.
First assume the "center of mass" (mean value of rows) is 0. Then PCA = SVD. The biggest eigenvalue/eigenvector points in the direction of largest variance, and so on for the second, third, fourth, etc eigenthings.
In the case where center of mass is not zero, SVD gives you the same data as PCA, it just takes into account that the center of mass has moved.
Its this lecture
ruclips.net/video/ey2PE5xi9-A/видео.html
He’s the best.
Sir You are wonderful and beautiful mathematician Thank you so much for teaching us for being with us
Thank you Prof Gilbert.
at around 37:15 when the Sir is talking about difference in Least Squares and PCA. I think minimization will lead to same solution as perpendicular length is proportional to other line. Hypotenuse * sin(theta), where theta is the angle between vertical line and the line of least squares which must be fixed for a particular plane(line). I could not understand where I am going wrong.
Where r u from
@@AmanKumar-xl4fd ??
@@KapilGuptathelearner jst asking
Very nice doubt bro. The catch is in the theta. Let us assume that first you used least squares and found out a line such that error is minimum and it is equals to E. Then as you said the error in case of PCA should be sin(theta) * E , here change in theta will have a direct effect to minimize error of PCA since it is in the product. So minimizing just E will not work, as you should minimize the product, and sin(theta) is also there. I hope you got i want to say.
@UCjU5LGbSp1UyWxb8w7wPE6Q u know about coding
28:50 Isn't it wrong to say that Square(Qv) = Transpose(Qv) * (Qv)? I think Square(Qv) = (Qv) * (Qv).
Can anyone explain whats relation of Eckart Young theorem and PCA ?
Where is continuation? It must have been on Friday as Prof announced. But lecture 8 is not that lecture. Right?
I'm looking for it too.
Desperately waiting for that Friday for MIT to upload.....
Good lecture, but I feel it only just starts getting into the heart of PCA before it ends. I don't see a continuation of the the discussion in subsequent lectures, so I'm wondering if I'm missing something.
Yes you are right. Do you know any other good source to learn PCA of this quality? Am having a hard time finding
@@rahuldeora5815 This one seems pretty nice for more information on PCA: ruclips.net/video/L-pQtGm3VS8/видео.html
@@ElektrikAkar thanks for that, I've wasted a huge amount of time looking for a good source
nice lecture loved it
@@ElektrikAkar
I just have one question not addressed in this lecture...what actual color is the blackboard?
Thank, Pr... Very helpful!
It seems that Prof. Gilbert Strang is a fan of Gauss.
0:37 what is a pca(?
@2:48 Why'd he have the chalk in his pocket?
5:56 vector norm matrices
I always thought the N-1 was related to the fact that the variance of a single object is undefined (or at least nonsensical), so the N-1 ensures this is reflected in the maths? As well as something related to the unbiasedness of the estimator etc.
This is called Bessel’s correction. I prefer to think that dividing by N-1 yields an unbiased estimator, so that on average the sample cov matrix is the same as the cov matrix from the pdf.
How can I find the proof of Eckart-Young theorem mentioned in the video? Where is the link?
The course materials are available at: ocw.mit.edu/18-065S18. Best wishes on your studies!
44:00 covariance matrix
Gauss or Euler?
ancient indian mathematicians knew about Pythagors thrm and euclidean distance
31:00 PCA
Great lecture! Thank you so much Prof. Gilbert Strang. But can anyone tell me where to find the following part of PCA?
Does anyone know where the notes are?
Most of the material is in the textbook. There are some sample chapters available from the textbook, see the Syllabus for more information at: ocw.mit.edu/18-065S18.
16:55 There was a joke that we didn't get to hear :(
Good. But I wish proof was given
7:09
4:26 norm
Minimise- use L1
18:00 nuclear norm- incomplete matrix with missing data
Нихера не понял, но лайк поставил)
xaxa
20220526 簽