He has this incredible gift of explaining something complex very simply and in a relaxed manner. I watched other videos about Spark and got nowhere. When I watched this, I felt like I now know Spark. I'll probably watch his advanced video.
Thanks a lot for your comment! Spark is a pretty easy to use system and I hope you keep exploring Spark Machine Learning and Spark Streaming, which I didn't have time to cover in this presentation.
Hi Sameer,what a great presentation in a short amount of time and a plethora amount of information with hands on practical.I am really amazed by your knowledge and presentation skills.Hats off for you Mate.Well done!!!!!
Hi Sammer, very interesting tutoriel. In 59:09 you are saving the content of the DataFrame from memory to a file, I have tried this but the problem when reading the file I didn't find the same number of partitions. Is there any configuration parameter to correct this issue? Thanks.
Sameer, I do not have any question for you - but just wanted to say Thank You very much for explaining Apache Spark in most simplistic way. Very good job !! I definitely gonna search for your more videos here - if you have your own secret channel for technology trainings - please do let me know. Thanks,
Sameer Farooqui Is there any other session on Spark ML On such datasets going to happen in future?Like the one you quoted as " Trying Decision Trees to predict the boolean column" in this video. Thanks
Hey Rahul, I dunno, maybe in a month I could do another recorded talk on actually implementing ML like decision trees on a data set. No definitive plans yet though.
Thank you so much Sameer for explaining this in such a wonderful way so I can get to know many basic as well as in depth knowledge in spark. I appreciate your help.
Hi sameer . I appreciate your long tutorials on pyspark. I am new to it and learning on my own. Just want to understand if i want to do any cosine similarity in a tfidf matrix how to go about it. I have tfidf in mappartition rdd
Hi Sameer, Your video on Spark is very educative. The 2 links beside "Labs" and "Learning Material" do not open any page. So can you give me the links from where I can download these files? Also, can I import this 1.5GB dataset into my own Databricks Community Edition without downloading the entire dataset and use it? Will look forward for your inputs..
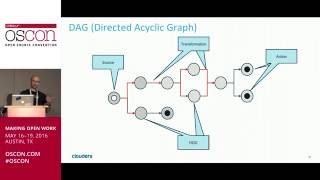
Is that possible to visualize data lineage (how each column was transformed, instantiated/derived from another column(s) - maybe using DAG?) BTW: That was an outstanding presentation, so much useful information in such discreet period of time! Thank you very much for that
wow! Amazing , Very detailed and clear. I have watched 3 times in last 2 days still so much to grab . Very hard to believe , 2 guys don't like to this video .
In cmd 47, for show() there are two parameters. Can we use only "false"? Bcoz we don't know how many rows we will get. So can we use any alternative for first parameter without hardcoding it as 35. Because I need false as my second parameter. However only false is throwing error
Hi Sameer, I am trying your example with Spark 2.1, and when I use the caching option to cache table and run the count it is throwing an error.. #spark.catalog.cacheTable("FSView") FSViewDF = spark.table("FSView") FSViewDF.count() Commenting out the cache statement returns the correct value, is this a change in behavior with Spark 2.1 ?
Hi Sameer. Thanks a lot for very nice explanation. Currently I am using Dataframe form Spark1.6 (Pyspark). 1st question: I would like to know will there be any performance impact when we will use Dataset in spark2.0 in terms of Pyspark/Scala. 2nd : I would like to know which language would be great to do ML in spark.
For ML in Spark, Scala will give you the latest algorithms, including alpha/experimental ones. Typically the algorithms are ported to Python or R a few months later. However if you're using the newer, DataFrame-based spark.ml package in MLlib, then feel free to use Python, R, Scala or Java (if the language has the algorithm you need), b/c the performance will be basically the same. If you use the older RDD-based spark.mllib package, then you're probably better off using Scala or Java. Regarding the first question, if you're using Datasets in Spark 2.0 w/ Scala, then you will get excellent speed and type safety. The main thing to understand is that when you use SQL queries, then both syntax and analysis errors are caught at runtime. With DataFrames, syntax errors are caught at compile time, while analysis errors are caught at runtime. Finally, with Datasets (best option), both syntax and analysis errors are caught early at compile time. If you're using PySpark, UDFs will run much slower in Python processes next to the Executor JVMs. So, as long as you're not using custom UDFs, then you should be fine with Python b/c the rest of the SQL/DF/DS code and function calls will run at native speeds in the JVM (as fast as scala/java). If you really need UDFs in PySpark, consider writing them in Java as Hive UDFs and then import then into PySpark... then you get the best of both worlds... Python and JVM based UDFs.
Hi sameer, Can I use some other data from the same data set site like crime data of SF and work on the same cluster? If not then how should I proceed with the crime data?
+NewCircle Training hy fantastic tutorial but i had a question about your old android internals tutorial can you please make a new tutorial since most of the things are outdated and one more thing since win10 has bash can i use it to build a rom ?
excellent !! is there any way to learn more from you sameer ? Can you guide or help us underastanding the concepts in person or in any other way. please let me now.
Hey, sorry I don't teach big data classes any more since joining Google, but if you follow me on LinkedIn or Twitter, I am planning on posting some Deep Learning & TensorFlow tutorials on RUclips later this year.
Great! I am beginner on Spark and i would like to compute some joins with 4 CSV files so that at the end i would have one dataframe. File1 is about 8GB, File2 5MB, File3 5MB, File4 15MB, File5 150MB. - I loaded the files, saved them as Parquet, read them again and finaly i created views (createOrReplaceTempView) of these dataframes. - I join dataframe_File1 with dataframe_File2 as merge1. - Now i would like to save merge1 as parquet again, read it an do others merges and so on... probleme: - merge1.spark.read.parquet(/path) lunch the spark Job and the job hangs. Any Suggestions? PS: I am using a standalone cluster (1 master = 1 slave). I did some join optimization concepts and configurations(shuflle.partitions, etc..) Best regards.
I have one question about no of partitions. as we get 13 partitions from a file of 1.6 GB, in this case each partitions has size of 128MB, whereas you mentioned that Spark read 64MB at a time. It's 128MB .. right?
Great work Sameer! Quick question: the sfopenreadalong link on your second slide seems to be broken (404 error). Do you have any other URL to suggest to access that file ? Thank you
1.Is there a JDBC/ODBC connectivity to Teradata from SPARK2.0 , to access the table directly?2.The file on S3 is not accessible. can this be made accessible?
Yeah, check out the Spark Docs in Apache for info about the JDBC connector. It exists. And to use the file in the demo, you'll need to import the notebooks and then mount the S3 bucket (see instructors in the first 10 mins of video).
pandas2016DF = joinedDF.filter(year('CallDateTS') == '2016').toPandas() When I this code in cmd135 , I got an error which is ValueError: Cannot convert NA to integer Please help!
Does display() function specific for Databricks notebooks? I use Zeppelin and I have searched for and looked api document, but found nothing. How can we use display() function?
It is specific Databicks's function. It is not Spark function. For to workaround. I use pandas instead. It works as expected. You can follow code snippet below: import pandas as pd pd_df = fireServiceCallsTsDf.limit(10).toPandas() pd.set_option('display.max_columns', None) pd_df
Hi Sameer... This was a Excellent session. I am just started my Journey with Spark. I had also viewed your RUclips long 6 hr video on Advance Apache Spark. It was also Excellent... Actually I am planning for pursue Certification in Spark, but found that all the vendors use old Spark versions for their Certifications Even Databricks uses Spark 1.1... Would that certification help for entering into this BiGData, Spark domain? Should I wait? I am like confused... Please get back with your inputs.....
Hey Abhay... focus on learning Spark 2.0 and the new Structured Streaming API. I wouldn't bother learning Spark 1.x today if you're just starting your Spark journey.
If you're using Databricks, then it's best to store the data on S3 within the AWS ecosystem. But if you're using open source Apache Spark, then you can use it within Google's cloud. From Google's website: "The Google Cloud Storage connector for Hadoop lets you run Hadoop or Spark jobs directly on data in Cloud Storage."
Databricks supports Python, Scala, R or SQL in their interactive notebooks. You can also use other 3rd party notebooks with Spark like Zeppelin notebook or Jupyter with a Spark/Scala kernel.









He has this incredible gift of explaining something complex very simply and in a relaxed manner. I watched other videos about Spark and got nowhere. When I watched this, I felt like I now know Spark. I'll probably watch his advanced video.
Thanks a lot for your comment! Spark is a pretty easy to use system and I hope you keep exploring Spark Machine Learning and Spark Streaming, which I didn't have time to cover in this presentation.
Sameer is truly amazing, I haven't seen such good teacher in a long time
Fantastic tutorial!!!. Just a observation for viewers: The quality of the audio drops in 56:51 but back in 58:26.
This is the best and most simply-explained tutorial. Thanks for the great lecture
Hi Sameer,what a great presentation in a short amount of time and a plethora amount of information with hands on practical.I am really amazed by your knowledge and presentation skills.Hats off for you Mate.Well done!!!!!
Great job Sameer! Very well done demo that was super informative. Keep 'em coming! Thanks!
Excellent job Sameer! Thank you very much for the class.
Excellent Explanation Sameer!!!
This is so great. Perfect for someone who has a little Sql, Python, pandas experience. Thank you!
Hi, please could you send me labs file because the libk dosent work. Thank you
Hi Sammer, very interesting tutoriel. In 59:09 you are saving the content of the DataFrame from memory to a file, I have tried this but the problem when reading the file I didn't find the same number of partitions. Is there any configuration parameter to correct this issue?
Thanks.
Sameer, I do not have any question for you - but just wanted to say Thank You very much for explaining Apache Spark in most simplistic way. Very good job !! I definitely gonna search for your more videos here - if you have your own secret channel for technology trainings - please do let me know. Thanks,
Nah, no secret channel. I prefer to release any video recordings publicly via RUclips.
you might wanna check out his secret videos on some questionable websites
Sameer, you are a spark guru. Really appreciate your gesture and simplistic methodology to explain even to a non-technical person! Amazing job!!
Sammer i m new in Spark..but you gave me a lot information and a full vision about this powerfull tool.Thanks a lot!
you are amazing Sameer, was really good lecture and rich information
..I need course to learn how can deal with big data analysis in databricks by using spark/python
Thank You Sameer.I learned a lot about spark after watching your videos....Will be waiting for your next 5hrs hands on video in next Summit
It is so instructive presentation. Thank you so much Sameer.
This was great! Thank you very much Sameer!
Hi Sameer,
Great explanation. You have any recent video on youtube for Spark.
Thanks
Govind
Excellent presentation, thank you.
Sameer Farooqui Is there any other session on Spark ML On such datasets going to happen in future?Like the one you quoted as " Trying Decision Trees to predict the boolean column" in this video. Thanks
Hey Rahul, I dunno, maybe in a month I could do another recorded talk on actually implementing ML like decision trees on a data set. No definitive plans yet though.
Thank you so much Sameer for explaining this in such a wonderful way so I can get to know many basic as well as in depth knowledge in spark. I appreciate your help.
Great job Sameer!!!!!!. Looks like your 6 hr video on spark is blocked in India. Please could you fix that as that was very useful.
This was excellent. Thank you!
Very informative and nicely presented.
8:50 minutes into the clip, it shows an amazon access-key-id along with the secret-access-key, I hope this pair is no longer active....
great video!
Thats a public key , its still active - It only help you to get that file he is sharing with everyone
Hi sameer . I appreciate your long tutorials on pyspark. I am new to it and learning on my own. Just want to understand if i want to do any cosine similarity in a tfidf matrix how to go about it. I have tfidf in mappartition rdd
Hi Sameer,
Your video on Spark is very educative.
The 2 links beside "Labs" and "Learning Material" do not open any page. So can you give me the links from where I can download these files?
Also, can I import this 1.5GB dataset into my own Databricks Community Edition without downloading the entire dataset and use it?
Will look forward for your inputs..
Is that possible to visualize data lineage (how each column was transformed, instantiated/derived from another column(s) - maybe using DAG?) BTW: That was an outstanding presentation, so much useful information in such discreet period of time! Thank you very much for that
wow! Amazing , Very detailed and clear. I have watched 3 times in last 2 days still so much to grab . Very hard to believe , 2 guys don't like to this video .
Johnie Harward hi johnie, thanks for your comment. I'm glad you found this useful.
The link to the Labs and Learning Material is no longer valid, could you update it?
In cmd 47, for show() there are two parameters. Can we use only "false"?
Bcoz we don't know how many rows we will get. So can we use any alternative for first parameter without hardcoding it as 35.
Because I need false as my second parameter. However only false is throwing error
Hi Sameer,
I am trying your example with Spark 2.1, and when I use the caching option to cache table and run the count it is throwing an error..
#spark.catalog.cacheTable("FSView")
FSViewDF = spark.table("FSView")
FSViewDF.count()
Commenting out the cache statement returns the correct value, is this a change in behavior with Spark 2.1 ?
spark.catalog is typically used for accessing metadata in parquet/hive. Try running spark.cacheTable("tableName") instead.
Hi Sameer Awesome session.
Great.. nice presentation with more learnings..
not able to download the lab files
this is gold
Hi Sameer. Thanks a lot for very nice explanation. Currently I am using Dataframe form Spark1.6 (Pyspark). 1st question: I would like to know will there be any performance impact when we will use Dataset in spark2.0 in terms of Pyspark/Scala. 2nd : I would like to know which language would be great to do ML in spark.
For ML in Spark, Scala will give you the latest algorithms, including alpha/experimental ones. Typically the algorithms are ported to Python or R a few months later. However if you're using the newer, DataFrame-based spark.ml package in MLlib, then feel free to use Python, R, Scala or Java (if the language has the algorithm you need), b/c the performance will be basically the same. If you use the older RDD-based spark.mllib package, then you're probably better off using Scala or Java.
Regarding the first question, if you're using Datasets in Spark 2.0 w/ Scala, then you will get excellent speed and type safety. The main thing to understand is that when you use SQL queries, then both syntax and analysis errors are caught at runtime. With DataFrames, syntax errors are caught at compile time, while analysis errors are caught at runtime. Finally, with Datasets (best option), both syntax and analysis errors are caught early at compile time.
If you're using PySpark, UDFs will run much slower in Python processes next to the Executor JVMs. So, as long as you're not using custom UDFs, then you should be fine with Python b/c the rest of the SQL/DF/DS code and function calls will run at native speeds in the JVM (as fast as scala/java). If you really need UDFs in PySpark, consider writing them in Java as Hive UDFs and then import then into PySpark... then you get the best of both worlds... Python and JVM based UDFs.
I cant able to open this link for labs and learning material please update it
It will be helpful for me
Awesome video. Thanks for sharing
Hi sameer,
Can I use some other data from the same data set site like crime data of SF and work on the same cluster?
If not then how should I proceed with the crime data?
Awesome training
+NewCircle Training hy fantastic tutorial but i had a question about your old android internals tutorial can you please make a new tutorial since most of the things are outdated and one more thing since win10 has bash can i use it to build a rom ?
excellent !! is there any way to learn more from you sameer ? Can you guide or help us underastanding the concepts in person or in any other way. please let me now.
Hey, sorry I don't teach big data classes any more since joining Google, but if you follow me on LinkedIn or Twitter, I am planning on posting some Deep Learning & TensorFlow tutorials on RUclips later this year.
thank you for your reply sir, sure I do.
Arun Goudar ..I need course to learn how can deal with big data analysis in databricks by using spark/python
Does Driver JVM has just 3 Executors in each case or even it can be changed?
wow this is so awesome
Thank you for this great intro to Spark!
Great!
I am beginner on Spark and i would like to compute some joins with 4 CSV files so that at the end i would have one dataframe. File1 is about 8GB, File2 5MB, File3 5MB, File4 15MB, File5 150MB.
- I loaded the files, saved them as Parquet, read them again and finaly i created views (createOrReplaceTempView) of these dataframes.
- I join dataframe_File1 with dataframe_File2 as merge1.
- Now i would like to save merge1 as parquet again, read it an do others merges and so on...
probleme:
- merge1.spark.read.parquet(/path) lunch the spark Job and the job hangs.
Any Suggestions?
PS: I am using a standalone cluster (1 master = 1 slave).
I did some join optimization concepts and configurations(shuflle.partitions, etc..)
Best regards.
Hi Sameer, Where can I get those files. The links you've shown appears to be broken.
I have one question about no of partitions. as we get 13 partitions from a file of 1.6 GB, in this case each partitions has size of 128MB, whereas you mentioned that Spark read 64MB at a time. It's 128MB .. right?
Great work Sameer! Quick question: the sfopenreadalong link on your second slide seems to be broken (404 error). Do you have any other URL to suggest to access that file ? Thank you
Hey! Did you ever find another working link?
@@mahumtofiq4930 unfortunately not
@@eljay0 aww man!
Thanks for replying though!
1.Is there a JDBC/ODBC connectivity to Teradata from SPARK2.0 , to access the table directly?2.The file on S3 is not accessible. can this be made accessible?
Yeah, check out the Spark Docs in Apache for info about the JDBC connector. It exists.
And to use the file in the demo, you'll need to import the notebooks and then mount the S3 bucket (see instructors in the first 10 mins of video).
Guys what are the best steps in learning Data Science...
pandas2016DF = joinedDF.filter(year('CallDateTS') == '2016').toPandas()
When I this code in cmd135 , I got an error which is
ValueError: Cannot convert NA to integer
Please help!
I am starting learning spark from your video but not able to get the labs file. Any help?
can you please renew the links for the lab data and learning material, they have gone down.
Does display() function specific for Databricks notebooks? I use Zeppelin and I have searched for and looked api document, but found nothing. How can we use display() function?
It is specific Databicks's function. It is not Spark function. For to workaround. I use pandas instead. It works as expected. You can follow code snippet below:
import pandas as pd
pd_df = fireServiceCallsTsDf.limit(10).toPandas()
pd.set_option('display.max_columns', None)
pd_df
GREAT JOB .
Provided links are not working so i am not able to start the tutorial
Great lecture! Thank you !
great intro :)
Hi Sameer... This was a Excellent session. I am just started my Journey with Spark. I had also viewed your RUclips long 6 hr video on Advance Apache Spark. It was also Excellent...
Actually I am planning for pursue Certification in Spark, but found that all the vendors use old Spark versions for their Certifications Even Databricks uses Spark 1.1... Would that certification help for entering into this BiGData, Spark domain? Should I wait? I am like confused... Please get back with your inputs.....
Hey Abhay... focus on learning Spark 2.0 and the new Structured Streaming API. I wouldn't bother learning Spark 1.x today if you're just starting your Spark journey.
Thanks a lot Sameer for your inputs...
can u run scala code in cells like pyspark
is lab file is still accessible?
Can we attach data stored in google cloud platform instead of aws?
If you're using Databricks, then it's best to store the data on S3 within the AWS ecosystem. But if you're using open source Apache Spark, then you can use it within Google's cloud. From Google's website: "The Google Cloud Storage connector for Hadoop lets you run Hadoop or Spark jobs directly on data in Cloud Storage."
Why does he look like that antagonist in venom movie ??
I see you run Databricks in Python but if i need run in Scala? how i do this ? pls Help :)
Databricks supports Python, Scala, R or SQL in their interactive notebooks. You can also use other 3rd party notebooks with Spark like Zeppelin notebook or Jupyter with a Spark/Scala kernel.
Gold :)
apache spark 2.0 release date?
it's in release candidate 4 now, should be within a week or two.
Dude u look like the guy from Nightcrawler movie.
Great work. Thanks a lot