Graph Convolutional Networks using only NumPy

HTML-код
- Опубликовано: 5 окт 2024
- Join my FREE course Basics of Graph Neural Networks (www.graphneura...! Implements Graph Convolutional Networks from scratch to translate the paper's equations into code. Applies this to Zachary's Karate Club graph as an example.
Code: github.com/zjo...
Original paper: arxiv.org/pdf/...
Message Passing video: • Simple Message Passing...
GCN blog post: blog.zakjost.c...
Mailing List: blog.zakjost.c...
Discord Server: / discord
Blog: blog.zakjost.com
Patreon: / welcomeaioverlords




![KAYTRANADA - Witchy (feat. Childish Gambino) [Official Video]](http://i.ytimg.com/vi/jGK3YVmGZ3Y/mqdefault.jpg)



UPDATE: As @HaoDong Zheng pointed out in the comments, there is an error in the formula for the "backward" pass of the GCN layer. I calculated the derivative with respect to A*X, but I should have calculated the derivative with respect to X (which gives you an "A" to multiply). I have made these changes to the code: github.com/zjost/blog_code/blob/master/gcn_numpy/gcn_from_scratch.ipynb
Finally understand GCNs in the most intuitive sense, thanks to your amazing explanation!
This is simply Brilliant. You teach Theoretically, Intuitively & Visually!! Kudos to your great research and teaching style!
Awesome stuff! Great use of Manim too, you need to give us a tutorial Zak!
Been waiting for this video since your first introduction to GCNs. Thanks a lot again Zak!
Fantastic video! Thank you for saving my butt with my research, I wish I could thank you in person
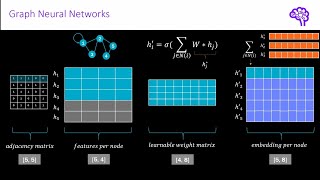
Graph Convolution can be easily understood by comparing it with a simple 2D convolution. A 2D convolution with window size 3 x 3 x Z channels can be broken down into 9 2D convolutions with window size 1 x 1 x Z that are subsequently shifted up, down, left, right, or diagonally and summed together. 2D convolution determines the how the values in the 9 feature maps are summed together under-the-hood, while graph convolution lets the programmer decide by using gather and scatter ops. This lets us get more creative and have more complex routing than merely routing every patch of 3 by 3 pixels to a corresponding output pixel/activation/node/feature map value.
Great explanation! Especially how you implement them with numpy, amazing
Thank you !! This is the best explanation I've seen on this subject :)
Thanks for this great tutorial. Most of the doubts are cleared !!!
Graph Convolutional Networks and Baroness on the same video. You are already my hero!!
In that case, you're *really* going to like my next video. Stay tuned.
@@welcomeaioverlords I'm subscribed (and bell icon) already! :)
Red Album \m/
Absolutely great lecture.. I have a request from you. can you please also explain the graphSage and GAT? that would really be amazing for us.
Thanks for the video.
Great video! One day I would also like you to play some of your electric guitar!!!
ruclips.net/video/WLTzbEKTxhk/видео.html
Love this, thanks!
Thank you for your explanation! perfect!
Great tutorial. Helped me a lot to understand the basics. Could it be possible to make a tutorial for graph classification also? The tutorials I have found so far with the classical protein data set are a little bit hard for me to follow. I have some graphs which all have the same number of nodes and edge connections with each node having only one feature and I want to apply binary classification on them.
Great Job !
Thank you
thank you for this great series!!! The learnable weight matrix initialisation in this code is W(out,in) - isn't it supposed to be other way around?
Edit: I looked at your code in more detail - you use a transpose operation inside the forward layer. Maybe that takes care of it?
What do you think about categorical edges in something like Knowledge Graphs?
Would we need separate Adjacency matrices for each type of relation?
Hey Connor! Do you mean basically a heterogeneous graph, where there are edges of different type (e.g. Person-follows-Person vs Person-blocks-Person in a Twitter context)?
In that case, yes, I think you're right. An example data structure is in DGL (docs.dgl.ai/generated/dgl.heterograph.html#dgl.heterograph), which basically uses a (SOURCE, RELATION, TARGET) as a key in a dictionary, which then maps to an edge list. This is essentially a sparse adjacency matrix for each relation tuple.
You might also check out the Relational-GCN paper. The equations show a sum over neighbors *of a particular type*, which implies a separate adjacency matrix. These relation types also get their own projection matrices.
@@welcomeaioverlords Really cool, thanks for sharing this! Trying to think about how that might blow up computationally, maybe not too unreasonable. Pretty random example, but I was just looking into a COVID Knowledge Graph titled "CoV-KGE", where they describe using 39 edges across 24 million nodes / 15 million of these edges. Doesn't seem too crazy to have 39 separate adjacency matrices. Maybe want to encode relations in vectors as well so you have like an adjacency tensor instead.
Thanks for the recommendations, will come back if I find anything interesting that builds on this idea haha!
awesome!
Wonderful video. I am working in Virtual Network Embeddings (VNE) using Meta-Heuristic. My next step is to adapt VNE to GNN. I would like your help! Good Job and Salute From Brazil.
Why do you set the features to the identity matrix? Like what's the theoretical motivation?
it seems to be wrong, the paper does not use sigma(wAH), it use sigma(something x H x W) instead (as denoted by equation 2 )????. It seems you have reverse the order of multiplication ?
will you be putting up the links you reference in the video? Thank you for these videos. They've been a great resource.
Whoops, thanks for pointing this out. I think the description has everything now. Cheers.
why can't you use XGboost or decision trees for node level classification instead of GCN?
Hello Zak. Can you please do the GCN implementation part for any excel dataset, it would be of great help!
how can i use other dataset with this code ?does anyone know ?
i wanna know too
Thanks for the great videos...
I am struggling to understand the dimensions of the weight matrix used in GCNs. Any help is appreciated/
It's the exact same as if it were a regular NN. The graph only is relevant when calculating the features (e.g., it smooths the features over the neighborhood by calculating A*X). Once it gets to the neural network part, it's exactly the same. So, the weight matrix will (h, d), where h is how large you want the output to be (a hyperparameter for you to choose) and d is the size of the features coming into the layer. Then you can calculate W*X.T to get something of size (h, bs), where bs is the batch size.
Thanks for your illustration. I am a beginner and facing a problem during running your code in Google colab. After executing the line _ = draw_kkl(g, None, colors, cmap='gist_rainbow', edge_color='gray') I got the following error: AttributeError: 'AxesSubplot' object has no property 'figsize'. Can anyone please help me? how to fix this?
You should have googled it, anyways now chatGPT can solve such problems easily !
Great explanation. Thanks. However, why X is the identity matrix with dimension(nodes=bs, nodes=bs) in gcn_from_scratch.ipynb? Shouldn't it be features matrix with dimension(nodes=bs, features=D)?
This is explained at 3:44.
@@welcomeaioverlords Thanks!
😍
Is GCN faster than DNN?
I think they work in 2 different ways. GCNs "encapsulate" the computations on features given the graph, thus this could slightly add more computation while training the model. Besides this, I think you would have pretty much the same layers you would implement in a DNN (except the situation in which you want to implement auto-encoders). Overall, I think the real question is which one best exploits the graph information for better results :)
@@hayleecs4223 i thought in graph network you can do parallel computation
@@ara7546 well, you can do parallel computation pretty much on anything if you can separate data without dependencies. I am currently conducting research on this topic but with CNNs. Graph Networks seem viable though
Thank you for sharing the video! Implementation using numpy is amazing. By understanding every line of ur code, everything becomes clear. Now I am wondering how to perform node prediction, edge prediction on more complicated GNNs, also trying to figure out how GNNs are used as recommender systems.
Edit: I think there might be a mistake in the optim.out at the backward function of the GCNLayer class, as we should output the gradient with respect to the input X instead of _X , so it should be A@(d2@self.W). I changed the code and found this led to much less training steps, around 1/6 of the original code, and lucky enough, it also led to better test set performance.
You're exactly right. I've made this change and pushed to the repo. I also added manual gradient checking on the input X, which would have caught this error. Thanks!
@@welcomeaioverlords My pleasure. Looking forward to more contents like this in the future!
A = nx.to_numpy_matrix(g) is showing error.
AttributeError: module 'networkx' has no attribute 'to_numpy_matrix'
anybody please!
They moved to `to_numpy_array`, and replaced the return object with an array instead of a matrix. See: networkx.org/documentation/stable/reference/generated/networkx.convert_matrix.to_numpy_array.html#to-numpy-array