Это видео недоступно.
Сожалеем об этом.
Cloud Run PubSub Consumer via Pull Subscription

HTML-код
- Опубликовано: 4 мар 2023
- I'm excited to share some of my recent discoveries on Cloud Run that I think many of you will find game-changing! In my opinion, there has been a gap in the serverless offerings that required running PubSub Pull Consumers on GKE - until now. With the introduction of Cloud Run Jobs, it's now possible to create real-time PubSub Pull subscribers with minimal engineering effort. This is a significant step forward and offers a fantastic alternative to running consumers on GKE. I can't wait to see the impact this will have and the exciting new possibilities it opens up!
00:30 - Topics to cover today
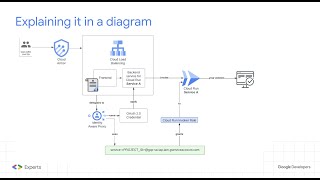
01:12 - Different ways to build a PubSub message consumer
02:10 - Why I think this isn't good enough
05:41 - PubSub Pull Consumer via a Cloud Run Job
07:02 - What do we want to achieve with this solution?
08:32 - Design Step 1, Build and Deploy the Cloud Run Job
09:28 - Design Step 2, Trigger Cloud Run Executions
10:44 - Design Step 3, Autoscaler
15:12 - Design, All together
17:14 - Code walkthrough
23:12 - Demo
30:26 - Summary
Additional reading
- Code: github.com/roc...
- Slide: docs.google.co...








Thanks so much for this video! I was looking at setting up a pull subscriber but didn't want to deal with managing a GKE instance and much prefer using Cloud run. Thanks again for the great video!
Glad I could help!
I implemented a similar solution using Cloud Workflows (CW) + Cloud Functions (CF). The CW runs a loop and makes N requests to the CF in parallel each iteration, where N is equal to the CF’s max instances. I’ll look into querying Stackdriver each loop to dynamically determine concurrency.
I chose CW over Cloud Scheduler (CS) for a few reasons. First, CS is limited to at most 1 run per minute, which wasn’t fast enough to keep my workers busy (they process a batch in under 30 seconds). Second, CS can’t make N requests in parallel so would required something in between to replicate the CW is doing. Third, CW has a configurable retry policy which is handy for dealing with the occasional CF network issues.
One caveat with CW is that a single execution is limited to 100k steps. To workaround this issue, I limit each CW execution to 10k loops, at the end of which it triggers a new workflow execution and exits. I setup an alerting policy to ensure there is always exactly 1 execution of this workflow running and haven’t had any issues.
Hmm, interesting approach. Although I am not sure we are comparing apples and apples here. The solution demonstrated in this video is an always on approach. In other words, the pull subscriber is always on listening to the PubSub subscriber, it doesn’t die after processing all remaining messages, but simply waits.
So if you change the interval of Cloud Scheduler to 10 minutes, and let the pull subscriber run for 9 minutes 50 seconds for example, it will not get killed until it reaches to that timeout (which is in the code example I gave).
I am not sure if I misunderstood you here, but the solution here is no different to what you would normally do with a GKE deployment, it’s just an alternative without needing any infrastructure.
That sounds correct! In my case the CF does a “synchronous pull” of a few thousand messages, processes them, and acks them all in bulk. So it’s not an always-on streaming setup like what you demoed here. It handles 1 batch per request, shuts down, and then is invoked again in the next loop by the CW.
For this particular use case, batching is advantageous so I went with synchronous pull. But it would be straightforward to switch the CF to a streaming pull if batching was not necessary.
🤩🤩🤩🤩🤩
This is truly amazing content! Thank you!
Glad it’s useful. Just keep in mind this is just an idea without using GKE for pull and still experimental. The recommended way is still using cloud run service with push unless you have a good reason not to do that (downstream batching , out bound etc)
@practicalgcp2780 Thanks a lot! I have a use case that I still don't know if I should use pull or push.
I have API Integrations with Facebook and Google Ads written in Python that request certain data and push it into BigQuery. In the future I will have more integrations, and would like to pull data from these APIs every 30 minutes. So I thought of implementing Pub/Sub to do this, so the requests come as messages, and the subscribers are the Python scripts deployed maybe in Cloud Run.
However, I'm not sure if I should use pull or push, and now after seeing your video, I'm worried about third party APIs failing, because also, as push rate scales exponentially, at the begining there will be many success responses, but then the API limits will be surpassed and it will fail a lot of times, to scale down again :/
@@SimonEcheverri7in this case what you can do is to convert the message into a unified format across all feeds in PubSub so all data are stored in one BigQuery table, or have one format per feed per topic so they go to different BigQuery table. And because the integration between PubSub and BigQuery, GCp has something out of the box you might want to have a look, I have another video for that where I explained the pros and cons ruclips.net/video/1JODJO6rLLA/видео.htmlsi=sAFNJ1heoZs6Ip7Q for efficiency this has been done traditionally using dataflow jobs, but that requires maintaining a pipeline yourself, the BigQuery subscription is created to simplify this.
In case you haven’t heard, cloud run job is in GA now!
Really interesting and informative. I'm currently looking at migrating away from a GKE workload purely because of the complexity, so this may prove useful. I'd be interested to know if you feel Cloud Run Jobs would support my use-case?
Essentially, based on a Pub/Sub message, I need to pull down a bunch of files from a GCS bucket, zip them into a single archive and then push the resulting archive back into GCS. This zip file is then presented to the user for download. There could be many thousands of files to ZIP and the resulting archive could be several terrabytes in size. I was planning on hooking up FileStore or GCS FUSE to Cloud Run to facilitate this. The original implementation was in Cloud Run (prior to jobs), but at the time, no-one knew how many files users would need to download or how big the resulting zip files would be. We had to move over to GKE, as we hit the maximum time limits allowed for Cloud Run, before it was automatically terminated.
Thanks for the kind comment. And it’s a quite interesting problem because the size of the archive can be potentially huge so it can take a long period of time. You are right. Cloud run service I think even today can only handle up to 1 hour timeout, cloud run job can handle 24 hours now. So if your archive process won’t take longer than a day i don’t see why you can’t use this approach. If you need longer time you can look at cloud batch, that can run longer without needing to create a cluster but it’s more complex the track the state of the operation. I have another video describing use cases using batch.
Having said that, it feels a bit wrong to have archives of huge size like that, have you considered options to generate the PubSub message from upstream systems in smaller chunks, or use the cloud run service to break things down and only zip so much files in a single execution, track the offset somewhere (I.e in a separate PubSub topic) to trigger more short lived zip operations? The thing is if there’s a network glitch which happens every now and then you could have wasted huge amount of compute.
Personally I would always prefer to make the logic slightly more complex in the code than maintaining a GKE cluster myself just to keep the infrastructure as simple as possible but that is just my opinion.
this seems like it adds more complexity than compared with the push model
Yes it does, but not everything upstream supports push model, plus not every downstream can handle the load via the push model. I explained some of the pros and cons, mainly related to controlling or improving throughput (I.e limiting how much traffic you want to consume if there is too much traffic or use batching). A really important thing to consider is the downstream and how many connections you establish, or how many concurrent requires you make if, I.e the downstream system is a HTTPS endpoint. Opening too many requests can easily overwhelm the system on the other side where if you batch the request or just open a single connection and reuse it makes a huge difference.
If it’s possible to use push without the constraints above, it’s almost always better to use push.
Hope that makes sense
Great content. Very helpful, thanks for the well prepared talk. We were wondering how to do this with pull and this gives us options.
Glad you found it useful! Just keep in mind of the cons, as the scaling part is not ideal. My preferred way to run it at this stage would be give it the resources for handling peak traffic (I.e. 5-6 workers instead of just 1-2), so you can keep the job running for longer without trigging it every few minutes. Usually this is doable as the consumers are usually quite lightweight, and quite easy to scale without needing too much cpu or ram per worker. Or if you can live with a bit of latency, less resources are fine too. And I would only use pull if you really need it such as having a downstream system requires batching or need to go through a Nat gateway for internet access to a 3rd party api. For all other use cases, push subscription with cloud run service would be the preferred way, much easier to scale and with better monitoring built into cloud run service.
And if you want a better scalable solution and don’t mind a bit of infra, check out this video on how to do this with GKE autopilot ruclips.net/video/DaopYyIhqJA/видео.html
@@practicalgcp2780 Thank you so much for taking the time for such a detailed reply. Your points make sense. We are currently using GKE and were evaluating simpler solutions. Your GKE autopilot suggestion was helpful, I'll check it out, thanks.
Thank you for your content! That helps a lot!
In the push model, when you say that the downstream system can not scale -> you mean for example an OLAP or OLTP DB where data will be hosted cannot handle that many requests?
When it comes to pricing, It seems that the push solution is the best right? Since it is supposed to perfectly "fits" to your workloads
Good questions again. And yes, kind of. But most I have seen having issues to scale are third party SaaS APIs wheee there are rate limits and you don’t want to hit these too often because it goes into exponential retries. Others just crashes when you send too much. Not going to mention the name of these vendors so I don’t get into trouble 😂 it’s also the NAT gateway won’t be able to handle that many outbound concurrent request (have a read about this if you are interested cloud.google.com/nat/docs/ports-and-addresses). So the pull solution in many scenarios works a lot better. Cost wise i think it’s the same. Both solutions you have to deploy cloud run with some workers, I tend to set it to 3, scaling to 0 you will get a cold start which for most APIs I work with that isn’t ideal. So the cost will be similar. Hope it makes sense.
@@practicalgcp2780 thank you for the answers! Yes, it totally makes sense! :)
@@practicalgcp2780 hello, thanks for the video...
I've been having the issues you described here trying to serve data into Aerospike (running onPrem) from Cloud functions/Cloud Run service.... It fails badly when there's a spike of messages in our pubsub topic. Is either the eventarc triggered function throttling cuz there are not enough instances or network problems cuz there are too many instances running and sending data through the VPC. i wanted to ask, does that approach using pulling subscriptions work the same if instead of using cloud run jobs I use cloud run services?? I have to use C# and it seems cloud jobs does not support it???
What's the advantage of this solution compared to implementing this within an AppEngine?
Do you mean via the HTTPS endpoint push subscription? That is also supported by cloud run and in fact is the recommended way to use push subscribers to get data out of PubSub as a subscriber service.
I don’t use app engine because it does not support VPC Service Controls (VPC SC) which is essential for large organisations from a security point of view.
The benefit of Pull is that in some use cases it is more efficient ( as it’s an event stream not individual request for each message), and it allows batching if you have a downstream system you need more efficient write. Most importantly if you have a downstream system cannot handle very high concurrency, the push subscription can create a bottleneck there or even kill the service.
Hope this answers your question