
- Видео 25
- Просмотров 473 494
Shusen Wang
США
Добавлен 20 авг 2020
Staff Engineer @ Meta
RL-1G: Summary
This lecture is a summary of Reinforcement Learning Basics.
Slides: github.com/wangshusen/DRL.git
Slides: github.com/wangshusen/DRL.git
Просмотров: 1 455
Видео


RL-1F: Evaluate Reinforcement Learning
Просмотров 1,2 тыс.3 года назад
Next video: ruclips.net/video/DLO401mNOw4/видео.html If you want to empirically compare two reinforcement learning algorithms, you will use OpenAI Gym. This lecture introduces three kinds of problems: - Classical control problems include CartPole and Pendulum. - Atari games include Pong, Space Invader, and Breakout. - MuJoCo includes Ant, Humanoid, and Half Cheetah. Slides: github.com/wangshuse...

RL-1E: Value Functions
Просмотров 3,3 тыс.3 года назад
Next video: ruclips.net/video/Rv7uC9v6Eco/видео.html Value functions are the expectations of the return. Action-value function Q evaluates how good it is to take action A while being in state S. State-value function V evaluates how good state S is. Slides: github.com/wangshusen/DRL.git

RL-1D: Rewards and Returns
Просмотров 1,5 тыс.3 года назад
Next video: ruclips.net/video/lI8_p7Qeuto/видео.html Return is also known as cumulative future rewards. Return is defined as the sum of all the future rewards. Discounted return means giving rewards in the far future small weights. Slides: github.com/wangshusen/DRL.git

RL-1C: Randomness in MDP, Agent-Environment Interaction
Просмотров 1,3 тыс.3 года назад
Next Video: ruclips.net/video/MeoSqrV5a24/видео.html Markov decision process (MDP) has two sources of randomness: - The action is randomly sampled from the policy function. - The next state is randomly sampled from the state-transition function. The agent can interact with the environment. Observing the current state, the agent executes an action. Then the environment updates the state and prov...
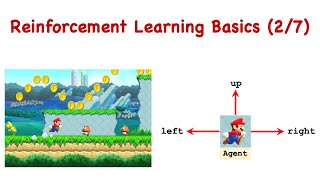
RL-1B: State, Action, Reward, Policy, State Transition
Просмотров 3,3 тыс.3 года назад
Next Video: ruclips.net/video/0VWBr6dBMGY/видео.html This lecture introduces the basic concepts of reinforcement learning, including state, action, reward, policy, and state transition. Slides: github.com/wangshusen/DRL.git

RL-1A: Random Variables, Observations, Random Sampling
Просмотров 3,1 тыс.3 года назад
Next Video: ruclips.net/video/GFayVUt2WGE/видео.html This is the first lecture on deep reinforcement learning. This lecture introduces basic probability theories that will be used in reinforcement learning. The topics include random variables, observed values, probability density function (PDF), probability mass function (PMF), expectation, and random sampling. Slides: github.com/wangshusen/DRL...
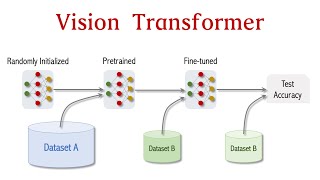
Vision Transformer for Image Classification
Просмотров 119 тыс.3 года назад
Vision Transformer (ViT) is the new state-of-the-art for image classification. ViT was posted on arXiv in Oct 2020 and officially published in 2021. On all the public datasets, ViT beats the best ResNet by a small margin, provided that ViT has been pretrained on a sufficiently large dataset. The bigger the dataset, the greater the advantage of the ViT over ResNet. Slides: github.com/wangshusen/...

BERT for pretraining Transformers
Просмотров 12 тыс.3 года назад
Next Video: ruclips.net/video/HZ4j_U3FC94/видео.html Bidirectional Encoder Representations from Transformers (BERT) is for pretraining the Transformer models. BERT does not need manually labeled data. BERT can use any books and web documents to automatically generate training data. Slides: github.com/wangshusen/DeepLearning Reference: Devlin, Chang, Lee, and Toutanova. BERT: Pre-training of dee...
Transformer Model (2/2): Build a Deep Neural Network (1.25x speed recommended)
Просмотров 13 тыс.3 года назад
Next Video: ruclips.net/video/EOmd5sUUA_A/видео.html The Transformer models are state-of-the-art language models. They are based on attention and dense layer without RNN. In the previous lecture, we have built the attention layer and self-attention layer. In this lecture, we first build multi-head attention layers and then use them to build a deep neural network known as Transformer. Transforme...
Transformer Model (1/2): Attention Layers
Просмотров 27 тыс.3 года назад
Next Video: ruclips.net/video/J4H6A4-dvhE/видео.html The Transformer models are state-of-the-art language models. They are based on attention and dense layers without RNN. Instead of studying every module of Transformer, let us try to build a Transformer model from scratch. In this lecture, we eliminate RNNs while keeping attentions. We will get an attention layer and a self-attention layer. In...
Self-Attenion for RNN (1.25x speed recommended)
Просмотров 8 тыс.3 года назад
Next Video: ruclips.net/video/FC8PziPmxnQ/видео.html The original attention was applied to only Seq2Seq models. But attention is not limited to Seq2Seq. When applied to a single RNN, attention is known as self-attention. This lecture teaches self-attention for RNN. In the original paper of Cheng et al. 2016, attention was applied to LSTM. To make self-attention easier to understand, this lectur...
Attention for RNN Seq2Seq Models (1.25x speed recommended)
Просмотров 30 тыс.3 года назад
Next Video: ruclips.net/video/06r6kp7ujCA/видео.html Attention was originally proposed by Bahdanau et al. in 2015. Later on, attention finds much broader applications in NLP and computer vision. This lecture introduces only attention for RNN sequence-to-sequence models. The audience is assumed to know RNN sequence-to-sequence models before watching this video. Slides: github.com/wangshusen/Deep...
Few-Shot Learning (3/3): Pretraining + Fine-tuning
Просмотров 30 тыс.3 года назад
This lecture introduces pretraining and fine-tuning for few-shot learning. This method is simple but comparable to the state-of-the-art. This lecture discusses 3 tricks for improving fine-tuning: (1) a good initialization, (2) entropy regularization, and (3) combine cosine similarity and softmax classifier. Sides: github.com/wangshusen/DeepLearning Lectures on few-shot learning: 1. Basic concep...
Few-Shot Learning (2/3): Siamese Networks
Просмотров 55 тыс.3 года назад
Next Video: ruclips.net/video/U6uFOIURcD0/видео.html This lecture introduces the Siamese network. It can find similarities or distances in the feature space and thereby solve few-shot learning. Sides: github.com/wangshusen/DeepLearning Lectures on few-shot learning: 1. Basic concepts: ruclips.net/video/hE7eGew4eeg/видео.html 2. Siamese networks: ruclips.net/video/4S-XDefSjTM/видео.html 3. Pretr...
17-4: Random Shuffle & Fisher-Yates Algorithm
Просмотров 2,1 тыс.3 года назад
17-4: Random Shuffle & Fisher-Yates Algorithm
5-2: Dense Matrices: row-major order, column-major order
Просмотров 4,5 тыс.3 года назад
5-2: Dense Matrices: row-major order, column-major order
5-1: Matrix basics: additions, multiplications, time complexity analysis
Просмотров 4,1 тыс.3 года назад
5-1: Matrix basics: additions, multiplications, time complexity analysis
Few-Shot Learning (1/3): Basic Concepts
Просмотров 76 тыс.4 года назад
Few-Shot Learning (1/3): Basic Concepts
2-1: Array, Vector, and List: Comparisons
Просмотров 4,2 тыс.4 года назад
2-1: Array, Vector, and List: Comparisons