if you are watching this in lockdown you are one of the rare species on the earth . many students are wasting their time on facebook, youtube, twitter, netflix, watching movies playing pubg, but you are working hard to achieve something . ALL the best ...nitj student here
I have recently been thinking of Data Science and Machine Learning, Krishna Naik's videos were very helpful in framing my decision. Thank you Krishna Naik.
That was an awesome journey.Now I have finished all the videos in the deep learning playlist. If you notice I have written a comment on each of the videos which was unnecessary.Now I will commence my journey to the ineuron course of Deep Learning with NLP which has commenced on the 18th of April. Oh Krish I wonder should review all the videos once again before commencing the journey of ineuron .Not a bad thought indeed. Ha!Ha!.Bye Krish .Stay blessed . Keep contributing.
sir g love ho gia ap sy main first time nlp smjny ki koshish kr raha tha q ky main ny final year my isy as a research work choose kia hy and sir your videos help me alot love you sir boht ziada
Hi , Thanks for your wonderful explanation, In my opinion , this detailed video is more important for researcher rather than programmers want to use LSTM or RNN
Me watching other YT videos: Watch then like/dislike/do nothing Me watching Krish sir's videos: First like then watch Thank you so much for explaining so many things. I learnt complete practical ML/DL from your videos. A big thumbs up from my side. Definitely, I will share your channel to anyone who would want to dive into ML/DL/DS.
Man You explain really great. I was confused in GRU and LSTM, your explanation was wonderful. Your skills gained one more subscriber to your channel. Thank You for such videos.
At 20:27 when context is similar , sigmoid(y) is vector[1 1 1 1], why will sigmoid(y)*tanh(y) give me vextor [0 0 0 0] , by looking at sigmoid and tanh graph when sigmoid(y) tends to -> 1 even tanh(y) graph tends to 1 , then sigmoid(y)*tanh(y) should result to vector [1 1 1 1] as well
Nice lecture sir. Plz, try to solve only one numerical example manually for at least one epoch sir. It will be helpful to understand lstm in depth. Thank you
I do not get something. We know that vanishing gradient problem is happening because the derivative of the sigmoid or tank function is between 0.25 max and 1 max and after many layers, the derivative cannot help in the update of the weight. However, here we are using sigmoid again. Aren't going to have the same problem
Hi Sir, I have a serious doubt. At 20:31 you are saying tanh will give output as 0000.. if context has not changed. How this happens plz elaborate that. I have spent a lot of time thinking on it bt still couldn't find the answer.
Sir, please upload videos on Boltzmann Machines...it feels very much complicated to understand the maths equations behind it...your videos has helped me a lot to learn ML/DL concepts Love ur videos♥️♥️
Hey Krish, it was a very informative video on the subject. thanks for the lovely work. I am not sure if I can request a topic that I and many others could be interested in. However, you being from an AI industrial side, it would be nice to see some content in the future about ml model encryption and resources for production. Great job on the youtube playlists
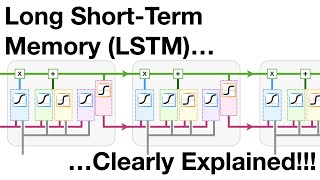
I'm having a feel that the equation mentioned at 10:40 isn’t right... For Ft = sig(Wf * [Ht-1, Xt] + Bf) Ht-1 should already have its weight associated, ie., Ht-1 = sig(Wt-1 * Xt-1 + Bt-1) , correct? Which means, for Wf, we won’t be factoring in Wt-1 into it again, but only use the current weight Wi Can someone comment on this and correct me if I'm wrong, please?
Hey krish could you like explain how each of the input features are mapped to the rnn units and how the ouputs are then formed? like im really having a hard time picturing how these input features are getting mapped at each time step? Like could you explain with this text sequence example itself where each word has n no. of features i.e is a vector of size n and how these features are mapped Thanks!!!
Sigmoid doesn't inherently converts real values to binary labels i.e. 0 or 1, instead it'll be range of real values between 0 to 1 (inclusive). The vectors at output of gates need NOT be something like [0 0 1 1] but can be, and most probably be, something like [0.122, 0.23, 0, 0.983].
Sir why are we again applying sigmoid function in the input layer while we have already done in the Forget Date? what is the necessity of calculating i(t) again? isn't f(t) = i(t)?
So is it fair to say the forget gate decides "where the new word fits in the context" and hence the forgetting in the context and the input gate decides how the new word 'changes' the context, thereby altering the influence of the new word on the context?
Sir, are you possible image classify of folder wise move. I'm data operator forest Kaziranga National Park. Many photos trapped camera. Manual segregation is to very hard. Please help you
At time stamp 7:00 i think this matrix multiplication not possible. In matrix multiplication, the number of columns in the first matrix must be equal to the number of rows in the second matrix for the multiplication to be valid.
So Inputgate is containing sigmoid and multiplication operation. same inputgate is involving in forget gate also. So forget gate is including input gate and output gate also including input gate. but output gate is something different like added tanh first then input gate . am i right ? anything wrong
Thanks for the video Krish. One doubt is, how would word vectors change to 0 & 1 when we pass through sigmoid function? Greater than 0.5 might mark as 1, but how is this probability determined? based on what value?
Sigmoid function is f(x) = 1/1+e^-x, after calculating value W.x + b this result passes through the sigmoid function which outputs value between 0 and 1. If output is greater than 0.5 then it is assigned 1 else 0 is assigned.
There's a mistake, the output of gate will be a vector of real values between 0 and 1 (inclusive) not binaries - i.e. not 0 or 1. Network learns best way to project, first by linear transformation (W times something) then by non-linear transformation (applying sigmoid). To answer your "how", the network "learns" what's best way to do this transformation (by learning weights) to optimize the objective function.
Hi Krish I have done with the lstm forecasting in that I am facing a data mismatch, like prediction was done for test data but the prediction data is lower than the test data
6:41 this is against the matrix multiplication rule, I was also doing the same manually for input layer, I was stuck for hours why I am not able to add the output to the memory state, then I found out that the I am applying wrong matrix multiplication rules. Anyways great Explanation.
Buddy, Even MIT did not go into the deep of it. Understanding the Math Behind the complex Deep Learning Networks are really complex. I was wondering that as the context changes, how the sigmoid function makes the value to 0 or near to zero to forget the past memory. Because the input is changing right? Then it must not proceed further..isn't it?
Few suggestion. Please reduce the frequency of words particular and over. As you already talk about something specific, it's not really needed everytime to use particular same way over. You are referring here, so simply here will sound good in place of over here.
LSTM is kinda crappy when it comes to predictions corona video cases. Krish according to you which algorithm should be the best to predict world's COVID-19 cases









if you are watching this in lockdown you are one of the rare species on the earth . many students are wasting their time on facebook, youtube, twitter, netflix, watching movies playing pubg, but you are working hard to achieve something . ALL the best ...nitj student here
self love is important......wts nitj?
@@aasavravi5919 it's NIT Jodhpur
Superb..100% true well said
@@aasavravi5919 nit JALANDHAR.
@@techtrader8434 Jamshedpur/Jaipur are also options
Ravi first time in this session I felt like lost . I loved your board presentation .
you are really lost he is Krish
I agree... This format is harder to follow.
@@shubhamsongire6712 lmao
@@shubhamsongire6712 🤣🤣
I have recently been thinking of Data Science and Machine Learning, Krishna Naik's videos were very helpful in framing my decision. Thank you Krishna Naik.
That was an awesome journey.Now I have finished all the videos in the deep learning playlist. If you notice I have written a comment on each of the videos which was unnecessary.Now I will commence my journey to the ineuron course of Deep Learning with NLP which has commenced on the 18th of April.
Oh Krish I wonder should review all the videos once again before commencing the journey of ineuron .Not a bad thought indeed.
Ha!Ha!.Bye Krish .Stay blessed . Keep contributing.
i also see your comments in every vedio.ha ha
Hello Sir, Is the concept of the video clear to you? If yes, Please help me with the same. Please reply on ritish_m@outlook.com
I was really strugling to understand the core concept of LSTM. This really helped me. Thank you very much,,Also the blog is really awesome..
@Krish Naik great video! the first video that gets to the point and explains concepts in detail.
sir g love ho gia ap sy main first time nlp smjny ki koshish kr raha tha q ky main ny final year my isy as a research work choose kia hy and sir your videos help me alot love you sir boht ziada
Hi , Thanks for your wonderful explanation,
In my opinion , this detailed video is more important for researcher rather than programmers want to use LSTM or RNN
Thank you, sir! It's great content and I'm almost following your NLP playlist.
Me watching other YT videos: Watch then like/dislike/do nothing
Me watching Krish sir's videos: First like then watch
Thank you so much for explaining so many things. I learnt complete practical ML/DL from your videos. A big thumbs up from my side. Definitely, I will share your channel to anyone who would want to dive into ML/DL/DS.
Man You explain really great. I was confused in GRU and LSTM, your explanation was wonderful. Your skills gained one more subscriber to your channel. Thank You for such videos.
At 20:27 when context is similar , sigmoid(y) is vector[1 1 1 1], why will sigmoid(y)*tanh(y) give me vextor [0 0 0 0] , by looking at sigmoid and tanh graph when sigmoid(y) tends to -> 1 even tanh(y) graph tends to 1 , then sigmoid(y)*tanh(y) should result to vector [1 1 1 1] as well
I have same doubt plz reply.
same doubt
Same doubt
Amazing explanation, you made it very simple and clear
This is the best explanation on LSTM.. really thanks
Wonderful video. Again great explanation. I think I might run out of words after a few more videos.
Nice lecture sir. Plz, try to solve only one numerical example manually for at least one epoch sir. It will be helpful to understand lstm in depth. Thank you
the best explanation as usual,, thank you so much for your effort.
watching it in 2024 from Pakistan... he saved me from failing NLP course... thank you
thanks so much my brother..great explanation .Allah bless you
I do not get something. We know that vanishing gradient problem is happening because the derivative of the sigmoid or tank function is between 0.25 max and 1 max and after many layers, the derivative cannot help in the update of the weight. However, here we are using sigmoid again. Aren't going to have the same problem
Thank You sir for such videos, Just please arrange it in playlist or in your website in order to access it easily. Thank You so much.
Tq for your unconditional service
Hi Sir, I have a serious doubt. At 20:31 you are saying tanh will give output as 0000.. if context has not changed. How this happens plz elaborate that. I have spent a lot of time thinking on it bt still couldn't find the answer.
Did you find answer to this bro? Even I came across the same doubt. It would be better if Krish could explain it.
@krish naik wonderfull explanation
Finest explanation of such a difficult topic, hats off!! 🫡
I have been waiting for this video so long.
good explanation i have ever seen ..
Sir, please upload videos on Boltzmann Machines...it feels very much complicated to understand the maths equations behind it...your videos has helped me a lot to learn ML/DL concepts
Love ur videos♥️♥️
Hi, Can you please tell me which all concepts in ML and DL you feel are mathematically complicated to understand?
Hey Krish, it was a very informative video on the subject. thanks for the lovely work. I am not sure if I can request a topic that I and many others could be interested in. However, you being from an AI industrial side, it would be nice to see some content in the future about ml model encryption and resources for production. Great job on the youtube playlists
Thank you so much sir, for such a great explanation
What happens to the -1 values of tanh and sigmoid cross product when the information is added to cell state in lstm?
nice! simple explanations.... much appreciable Sir
I'm having a feel that the equation mentioned at 10:40 isn’t right...
For Ft = sig(Wf * [Ht-1, Xt] + Bf)
Ht-1 should already have its weight associated, ie., Ht-1 = sig(Wt-1 * Xt-1 + Bt-1) , correct?
Which means, for Wf, we won’t be factoring in Wt-1 into it again, but only use the current weight Wi
Can someone comment on this and correct me if I'm wrong, please?
Hey krish could you like explain how each of the input features are mapped to the rnn units and how the ouputs are then formed? like im really having a hard time picturing how these input features are getting mapped at each time step? Like could you explain with this text sequence example itself where each word has n no. of features i.e is a vector of size n and how these features are mapped Thanks!!!
Sigmoid doesn't inherently converts real values to binary labels i.e. 0 or 1, instead it'll be range of real values between 0 to 1 (inclusive). The vectors at output of gates need NOT be something like [0 0 1 1] but can be, and most probably be, something like [0.122, 0.23, 0, 0.983].
Sir why are we again applying sigmoid function in the input layer while we have already done in the Forget Date? what is the necessity of calculating i(t) again? isn't f(t) = i(t)?
amazing explanation sir..many thanks
Wonderful Explanation!
So is it fair to say the forget gate decides "where the new word fits in the context" and hence the forgetting in the context and the input gate decides how the new word 'changes' the context, thereby altering the influence of the new word on the context?
Excellent sir
Hi, actually I don't understand why do we need to do the sigmoid part twice? Once for input and once for forget gate? Isn't it doing the same thing?
Bro I have the same doubt. The weights may change but doesn't that impact the model? Please let me know if you found any answer
Sir, are you possible image classify of folder wise move. I'm data operator forest Kaziranga National Park. Many photos trapped camera. Manual segregation is to very hard. Please help you
At time stamp 7:00 i think this matrix multiplication not possible. In matrix multiplication, the number of columns in the first matrix must be equal to the number of rows in the second matrix for the multiplication to be valid.
Excellent..
LSTM accepts input of variable size?? Or padding is required to make all input of same size?
hello Krish can you explain Conv-LSTM with one sample data and difference with LSTM and time distributed concept of LSTM?
Thanks Krish
How does long term dependency problem relates with Vanishing gradient problem , anyone plz explain ?
So Inputgate is containing sigmoid and multiplication operation. same inputgate is involving in forget gate also. So forget gate is including input gate and output gate also including input gate. but output gate is something different like added tanh first then input gate . am i right ? anything wrong
Hi krish ,
In lstm don't we have back propagation and weight updation ? if yes, why?
great explaination
Krish sir,how are the weights different at every gate?Since we are sending the same concatenated weights to every gate,how can it be different?
finally i saw detailed explanation. ty.
Bro because of you i understood deep learning very well I need a small help can u send some resources for learning deep learning with tensorflow pls
A small confusion in C t-1. How does Ct-1 differ from h t-1, if both are previous output
Thank you sir❤
Could you please make the video in seq2seq architecture for the Conversational Modeling?
Thanks for the video Krish. One doubt is, how would word vectors change to 0 & 1 when we pass through sigmoid function? Greater than 0.5 might mark as 1, but how is this probability determined? based on what value?
Sigmoid function is f(x) = 1/1+e^-x, after calculating value W.x + b this result passes through the sigmoid function which outputs value between 0 and 1. If output is greater than 0.5 then it is assigned 1 else 0 is assigned.
There's a mistake, the output of gate will be a vector of real values between 0 and 1 (inclusive) not binaries - i.e. not 0 or 1.
Network learns best way to project, first by linear transformation (W times something) then by non-linear transformation (applying sigmoid).
To answer your "how", the network "learns" what's best way to do this transformation (by learning weights) to optimize the objective function.
How can we do extractive summarisation in BERT??
Hi Krish I have done with the lstm forecasting in that I am facing a data mismatch, like prediction was done for test data but the prediction data is lower than the test data
is the video for the different types of LSTM skipped ?
@KrishNaik please could you tell what is the math behnid this concatenation operation [ht-1 ,xt] ? what is ',' ?is it addition , multiplication?
It is actually concatenation.. let say ht-1 is m size vector and xt is n size then resulting thing would be m+n size v vector
6:41 this is against the matrix multiplication rule, I was also doing the same manually for input layer, I was stuck for hours why I am not able to add the output to the memory state, then I found out that the I am applying wrong matrix multiplication rules. Anyways great Explanation.
it is hadamard product
Love your video, but I have a question so how do we update the weight or backproprogate the LSTM ?
I think the bacpropogation process of lstm rnn is same as simple rnn
Buddy, Even MIT did not go into the deep of it. Understanding the Math Behind the complex Deep Learning Networks are really complex.
I was wondering that as the context changes, how the sigmoid function makes the value to 0 or near to zero to forget the past memory. Because the input is changing right? Then it must not proceed further..isn't it?
Can you please make a video on how to combine two deep learning model which are trained on different dataset
please upload video any real time project in deep learning using like lstm algotihm
Few suggestion. Please reduce the frequency of words particular and over. As you already talk about something specific, it's not really needed everytime to use particular same way over. You are referring here, so simply here will sound good in place of over here.
Thanks Sir.
LSTM is kinda crappy when it comes to predictions corona video cases.
Krish according to you which algorithm should be the best to predict world's COVID-19 cases
Hello Sir, Is the concept of the video clear to you? If yes, Please help me with the same. Please reply on ritish_m@outlook.com
Sir how can we use time series data as input in CNN.please guid me
please upload time series analysis using RNN asap...
Yes coming up
Please help me to work with time series data
Could you please programming tutorial for lstm and GRU ?
Please upload further videos....
Is accuracy meaningless in keras models.....?
Thanks. Please upload LSTM video on practicals
Can anyone provide reference link to learn the word to vector conversion topics
go to deep learning playlist
Is there anything left with deep learning tutoril or it is completed
Can you please make a video on GAN as well?
Krish , Please upload more on LSTM .
Please go back to your whiteboard. You're amazing with whiteboard and marker!
i m waiting for ur next video
from which book you are teaching krish
link is given in reference kkk
Great
Will you be uploading videos on Transfer Learning ?
Transfer learning is a very broad topic bro everyday a new algorithm is comming using transfer learning
@@RinkiKumari-us4ej Hello Sir, Is the concept of the video clear to you? If yes, Please help me with the same. Please reply on ritish_m@outlook.com
Please upload video about autoencoder
so complicated ...
hehe😂
i think you have to clear your basics first
21:48 yes , very confusing
Day of Recording of this video is the day when the LOCKDOWN started !!!!!!!!
please upload more videos
Mar-24-2021
R u 29 years old?
board is more good
Паша Техник совсем плох, индусом стал, нейронками занялся
confusing
You disappointed us
😂
Too much advertisements😒😔
Hello all my name is Krish Naik...🤣😁😝