Want to learn more about the Technological Revolution? Watch our playlist here: ruclips.net/video/ENWsoWjzJTQ/видео.html - ALSO - Become a RUclips member for many exclusive perks from exclusive posts, bonus content, shoutouts and more! subscribe.futurology.earthone.io/member - AND - Join our Discord server for much better community discussions! subscribe.futurology.earthone.io/discord
This is next level explanation No seriously , so much efforts for this video are clearly seen 1. Visuals 2. Animation 3. Audio 4. Explantion 5. Clarity really really appreciated ✨✨ Will hit more then a Million views for sure
I almost agree with the comment, except with the prediction on the 1 million views. You need to be more specific with this objective, (or S.M.A.R.T.?) One year later is far from 1 million. And it's an amazing explanation.
This is hands down the greatest video I've ever seen explaining neural networks. The way you explain it is so simple and the visuals are astounding! You absolutely knocked it out of the park with this one!
Dude wtf, this video is absolute gold. I have read books and papers by expert in the field and I have also talked to ML experts and I can confidently say that this video did the absolute best job at breaking down all of these Conv Net concepts! The visuals with the explanation was extremely helpful. Thank you very much for creating this masterpiece.
Awesome video ! I usually watch videos on ytube @ 1.25 or 1.5 speed but this one deserves 0.75 in order to catch all the precious bits of information provided. Great production quality too. Thanks
THE PRODUCTION QUALITY. The ratio of it with the views and subscribers is WAY off. This deserves views in millions. Not to mention the way these complex concepts were explained, this is the best video I have ever seen for the explanation of CNNs. Hats off.
Amazing explanation, brilliant production quality and sleek animations. Hands down, one of the best places to get a high level view on machine learning topics available on YT. Thanks mate for the effort.
absolutely loved this. you can understand more about hyperparameters easily if you're well aware of how the network works which was very well explained in this video. i really loved this! kudos to the production/editing team and the narrator!
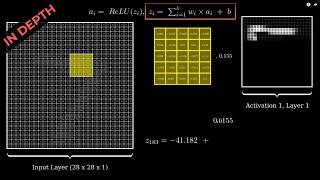
Question: at 6:21 if you have 16 filters for the next layer, given the fact that you have 8 inputs after max pooling, then the dimention of the feature maps should be 10*10*(16*6) rather than 10*10*16? How do you combine the outputs of the 16 kernels *6 inputer features to get 10*10*16 features maps? In other words, when you do the convolutions on the original image, you get 6 feature maps outputs because every kernel is applied to the orignal image. But after maxpooling, you have 6 images and applying 16 kernels on them should results in 6*16 feature maps.
@@hubble648 the filters dont add up to the next layer. For every layer the filters keep going up while the pixels keep going down. For example, the numbers in a conv layer 6*28*28 mean 6 filters*28(width)*28(height) totaling 4704 pixels across the 6 images. Next layer should be pool layer with 6*14*14 meaning 6 filters with 14 pixels width and height. This happens because the pooling layer is just keeping the most important features of the matrix in the previous conv layer and rejecting the insignificant ones which naturally results in a smaller matrix. Therefore, adding up the filters from previous layers to the new ones does not make sense like @jacobjonm0511 mention on 10*10*(16*6)
@@SANCHEZHERNANDEZDANIELALFONSO Thanks, I understood that part, but then how did it go from 6 14*14 layers to 16 5*5 layers? Do you know what kind of convolution he is doing?
@@hubble648 As i mentioned in my previous comment, it doesnt go from 6x14x14 to 16x5x5. It follows this route input --> conv1 --> pool1 --> conv2 --> pool2. Search ""Output Size Formula" in the context of CNN and you'll find the answer. After you check it, i recommend you to reread my previous comment for some more clarity. Hope that helps
@@SANCHEZHERNANDEZDANIELALFONSO You misunderstood me. I understood what you meant in the first comment. What I asked is that conv1 uses edge detection (horizontal, vertical and diagonal). I wanted to ask what kind of filters it uses in conv2.
this was really some awwesome level content filled to the brim with knowledge. i always wondered what those mesh like representation actually meant, this was really informative and layman friendly. moreover, i also come to wonder how does those resolution upscalers work, i mean they literally are making pixels and details out of thin air ( and memory maybe, idk its just a asumption on my side), but it will be fun knowing a lil bit more about it.
Thanks for watching! Upscalers typically use autoencoders (inverse graphics networks), we do plan on making videos on these networks and their applications in the future!
Mind blown 🤯. Love this explanation. i am subscribing just cause of this video. This is the the kind of fast and easy to understand video i was looking for
excellent video. Just one thing, as far as i know if you convolve an input image with 3 channels and a filter with the same number of channels, you end up with a feature map of one dimension instead of 3. Convolution happens for each channel between the input image and the filter and then you sum up the values between channels at every windowing step
This is next level explanation No seriously , so much efforts for this video are clearly seen 1. Visuals 2. Animation 3. Audio 4. Explantion 5. Clarity
I wonder how such calculations could have been carried out the first time when the computers weren't so advanced. The pioneers of AI are such brilliant people 🤝
I saw the video a second time but at 0.75X speed. way too better. so actually the information provided are decent and well structured, but the speed of presentation along with the noisy cuts make the experience difficult... good work though!
This seems like a product of a lot of work. It's quite good, except for the speed. Please consider slowing down, for everyone to fully understand the content.
Congrats for the animation dude! One of the best visualizations I have seen on the topic. The vaporwave music was also a nice touch. By the way, which software do you use to animate this?
How does CNN become rotation and orientation invarient? Can this be understood with a visualization using few images that rotation/re-orientated and then their output followed through the layers and architecture of CNN ?
Great video but the second convolution layer is poorly explained. If you have 16 kernels, are those applied to each of the 6 previous images? Then you counting of pixels are wrong but if not how do you produce those 16 5x5 images?
I love interactive tools like that number recognizer. Do you know of similar ones for more cnn's and/or other architectures? Text, image, any modality.
The section about audio at around 02:27 is bit (no pun intended) all over the place. First, at the most basic level, audio is not stored as frequencies, but as a series of values representing the relative position of the speaker's cone over time; but then also, while you said it was stored as frequencies, the illustration shows a grid of pixels depicting a low resolution representation of the waveform, which is neither the frequencies nor the the way the waveform is actually stored.
Hello guys, want to start a RUclips playlist for learning how to implement NN from scratch, have already started though, but am not really getting much audience But anyways , in the series, i teach how to implement NN in js and c++ from scratch, also explaining all the concepts that makes up a ANN and also a CNN👍 Is it ok if i leave a link to my channel??
Great video! Way more helpful then another online course I am taking from Carnegie-Mellon! That link to the interactive digit recognizer is dead... Has that been updated or is it just not available? Thanks!








![The moment we stopped understanding AI [AlexNet]](/img/1.gif)
Want to learn more about the Technological Revolution? Watch our playlist here: ruclips.net/video/ENWsoWjzJTQ/видео.html
- ALSO - Become a RUclips member for many exclusive perks from exclusive posts, bonus content, shoutouts and more! subscribe.futurology.earthone.io/member - AND - Join our Discord server for much better community discussions! subscribe.futurology.earthone.io/discord
talk about future of computing make a 2 hour video
how bio cpu or quantum cpu can change the world
talk about the future of pc, cpu and light speed cpu and more
the link for Interactive Number Recognizer is dead :(
You saved my ass with these sick visuals man I'm a student with without much money man it would be a crime not to pay for this
This is next level explanation
No seriously , so much efforts for this video are clearly seen
1. Visuals
2. Animation
3. Audio
4. Explantion
5. Clarity
really really appreciated ✨✨
Will hit more then a Million views for sure
I almost agree with the comment, except with the prediction on the 1 million views. You need to be more specific with this objective, (or S.M.A.R.T.?) One year later is far from 1 million. And it's an amazing explanation.
I agree, this is art.
Wow, the production value of this video is so high! The explanations are awesome too! Keep going. 💪
The sheer production effort went into this video blows my mind. The visualization aspect is just too good to be true. Thanks.
This is hands down the greatest video I've ever seen explaining neural networks. The way you explain it is so simple and the visuals are astounding! You absolutely knocked it out of the park with this one!
Well, I've watched 4 videos to understand CNN, and I can say this is the shortest and clearest one. Thanks, man!
Dude wtf, this video is absolute gold. I have read books and papers by expert in the field and I have also talked to ML experts and I can confidently say that this video did the absolute best job at breaking down all of these Conv Net concepts! The visuals with the explanation was extremely helpful.
Thank you very much for creating this masterpiece.
This is one of the best explanations and animations about deep learning!! Congrats for the amazing content!
I can not put into words how usefull this video is for visual learners. A big thank you!
Awesome video ! I usually watch videos on ytube @ 1.25 or 1.5 speed but this one deserves 0.75 in order to catch all the precious bits of information provided. Great production quality too. Thanks
U are seriously underrated bro. Great content and quality .❤️👍.
Jonkeen has a channel u should look up some of his older videos
@@rebeccarpwebb4132 name of the channel?
@@ksrikar6668 jonkeen and bestdamnpodcast.... Lots of videos . this video showed up under his . i find really good channels from his
Its small lil channel no commercials. This guy is just consumed with his research and i find it fascinating and lots of other good stuff to look up
I just want to add to what folks are generally saying: hands down one of the best videos about CNN's on RUclips
THE PRODUCTION QUALITY. The ratio of it with the views and subscribers is WAY off. This deserves views in millions. Not to mention the way these complex concepts were explained, this is the best video I have ever seen for the explanation of CNNs. Hats off.
dude this video is ultra high quality. you are criminally under sub
Amazing explanation, brilliant production quality and sleek animations. Hands down, one of the best places to get a high level view on machine learning topics available on YT. Thanks mate for the effort.
The visualizations just facilitate the understanding so much! Thank you!
Danke!
Really good stuff. The visualization is just amazing. Appreciate the hard work on this
One of the only good explanations of machine learning on RUclips, thank you.
Really needed this visualization to actually understand weeks' worth of university lectures...
absolutely loved this. you can understand more about hyperparameters easily if you're well aware of how the network works which was very well explained in this video. i really loved this! kudos to the production/editing team and the narrator!
one of the best youtube videos ive ever seen, big ups
After watching bunch of videos this just clicked and everything just clicked, thank you for this wonderful video.
This is amazingly visualised and explained. Visualization always really helps to understand the real pictures of the ideas, especially for beginners.
The visualization is simply phenomenal. Amazing job!
U got yourself a new subscriber.
I hope this channel blows up very fast.
I dont know how this content is free but thank you so so much!
Question: at 6:21 if you have 16 filters for the next layer, given the fact that you have 8 inputs after max pooling, then the dimention of the feature maps should be 10*10*(16*6) rather than 10*10*16? How do you combine the outputs of the 16 kernels *6 inputer features to get 10*10*16 features maps?
In other words, when you do the convolutions on the original image, you get 6 feature maps outputs because every kernel is applied to the orignal image. But after maxpooling, you have 6 images and applying 16 kernels on them should results in 6*16 feature maps.
yea, I'm confused too. He combines them together but doesn't tell us how he did it.
@@hubble648 the filters dont add up to the next layer. For every layer the filters keep going up while the pixels keep going down. For example, the numbers in a conv layer 6*28*28 mean 6 filters*28(width)*28(height) totaling 4704 pixels across the 6 images. Next layer should be pool layer with 6*14*14 meaning 6 filters with 14 pixels width and height. This happens because the pooling layer is just keeping the most important features of the matrix in the previous conv layer and rejecting the insignificant ones which naturally results in a smaller matrix. Therefore, adding up the filters from previous layers to the new ones does not make sense like @jacobjonm0511 mention on 10*10*(16*6)
@@SANCHEZHERNANDEZDANIELALFONSO Thanks, I understood that part, but then how did it go from 6 14*14 layers to 16 5*5 layers? Do you know what kind of convolution he is doing?
@@hubble648 As i mentioned in my previous comment, it doesnt go from 6x14x14 to 16x5x5. It follows this route input --> conv1 --> pool1 --> conv2 --> pool2. Search ""Output Size Formula" in the context of CNN and you'll find the answer. After you check it, i recommend you to reread my previous comment for some more clarity. Hope that helps
@@SANCHEZHERNANDEZDANIELALFONSO You misunderstood me. I understood what you meant in the first comment. What I asked is that conv1 uses edge detection (horizontal, vertical and diagonal). I wanted to ask what kind of filters it uses in conv2.
Excellent video. There are hundreds of similar YT videos but most are confusing. Yours is clear.
this was really some awwesome level content filled to the brim with knowledge. i always wondered what those mesh like representation actually meant, this was really informative and layman friendly. moreover, i also come to wonder how does those resolution upscalers work, i mean they literally are making pixels and details out of thin air ( and memory maybe, idk its just a asumption on my side), but it will be fun knowing a lil bit more about it.
Thanks for watching! Upscalers typically use autoencoders (inverse graphics networks), we do plan on making videos on these networks and their applications in the future!
@@OptimisticFuturology that's just great, and you're welcome.
Wow, the intuitive explanation and great production quality of this video makes this one of my favourites that I have watched on this topic 🎉
Mind blown 🤯. Love this explanation. i am subscribing just cause of this video. This is the the kind of fast and easy to understand video i was looking for
the best video for CNN i could ever find, seriously
Wow! This video is so great! Rarely do I see such a clear visualization of the topic!
excellent video. Just one thing, as far as i know if you convolve an input image with 3 channels and a filter with the same number of channels, you end up with a feature map of one dimension instead of 3. Convolution happens for each channel between the input image and the filter and then you sum up the values between channels at every windowing step
🙌.
Great Watch looking forward for next update
my friend..
This is next level explanation
No seriously , so much efforts for this video are clearly seen
1. Visuals
2. Animation
3. Audio
4. Explantion
5. Clarity
Brilliant explanation with Incredible animations. Really sutisfying to watch, when you see the process and understand it.
Amazing video! well-expanded and visually captivating 👏
You explained so much in such less time in such simple words. Huge thanks!
Hey Futurology, You saved my A** ...Love from Ethiopia!
great explanation, thankyou
Man, your work is Phenomenal!!! Thanks💯
What an ABSOLUTE BANGER! Shukran Habibi
How do you make these animations? They look great! Thanks for making it clearer what CNNs look like.👍
Thankyou for the brilliant explanation with the thoughtful graphics.
How does this not have a x million views, this is unreal
Great video, thank you so much, your efforts are highly appreciated!
This was a great explanation. Thank you. Now I feel like I can actually understand some other videos which dive a little deeper.
really nice work mate!
Next Level Explanation
Incredible explanation. Love your way how you work
This video needs to be appreciated 🎉❤
This explanation was outstanding!!!
visualizing it makes so much easier to understand. Thank you
Thank you for this video! It and others helped me pass my exam! :D
What a great video! Great production too! Let's get iiiit!
great video, visual illustrations of CNN working really help with undertstanding
Best Explaination i found wow, keep it up, so easy to understand thank you very much i got a exam about that tomorrow!
10 minutes of pure bliss!
Spectacular video!
insane job bro !!
love it. The is hands down the way to visualize how a CNN works in general
I wonder how such calculations could have been carried out the first time when the computers weren't so advanced. The pioneers of AI are such brilliant people 🤝
Great video, thanks so much!
THIS IS SO GOOD!!
these visuals are insane ??
The visuals were dope!
I sure am looking forward to the next episode in the series.
this explanation is overpowered
Great explanation!
beautiful explanation with visualization - easy to understand
I saw the video a second time but at 0.75X speed. way too better. so actually the information provided are decent and well structured, but the speed of presentation along with the noisy cuts make the experience difficult... good work though!
This was extremely well done
great demo thank u so much
Next level explanation
That's damn awesome. the visualizations are badly awesome
amazing video and amazing visualization
Awesome explaination sir, thank you
Awesome job. But i have 2 questions.
1) how to backpropagate a pooling layer.
2) how you went from 6 feature maps onto 16?
Best regards.
Thanks for the recommendation on brilliant!
This seems like a product of a lot of work. It's quite good, except for the speed. Please consider slowing down, for everyone to fully understand the content.
Thank sir making video you are doing great job
What kind of software used to create this masterpiece video🤔
Really good explanation!
Great video!
Congrats for the animation dude! One of the best visualizations I have seen on the topic. The vaporwave music was also a nice touch. By the way, which software do you use to animate this?
How does CNN become rotation and orientation invarient? Can this be understood with a visualization using few images that rotation/re-orientated and then their output followed through the layers and architecture of CNN ?
my brain is exploding but in a good way, thanks for this!
Great video but the second convolution layer is poorly explained. If you have 16 kernels, are those applied to each of the 6 previous images? Then you counting of pixels are wrong but if not how do you produce those 16 5x5 images?
I love interactive tools like that number recognizer. Do you know of similar ones for more cnn's and/or other architectures? Text, image, any modality.
THANK YOU SO MUCH
It looked like a holly wood movie.. Great explanation.. I totally liked it..
07:28, how did the feature maps count jump from 6 in Pool1 to 16 in Conv2 ?
The section about audio at around 02:27 is bit (no pun intended) all over the place. First, at the most basic level, audio is not stored as frequencies, but as a series of values representing the relative position of the speaker's cone over time; but then also, while you said it was stored as frequencies, the illustration shows a grid of pixels depicting a low resolution representation of the waveform, which is neither the frequencies nor the the way the waveform is actually stored.
Hello guys, want to start a RUclips playlist for learning how to implement NN from scratch, have already started though, but am not really getting much audience
But anyways , in the series, i teach how to implement NN in js and c++ from scratch, also explaining all the concepts that makes up a ANN and also a CNN👍
Is it ok if i leave a link to my channel??
Thank you very much!!!!
Great video! Way more helpful then another online course I am taking from Carnegie-Mellon!
That link to the interactive digit recognizer is dead... Has that been updated or is it just not available? Thanks!
best video!