Про multi stage pipeline очень вскользь сказано, хотелось бы на конкретном примере. Например как организовать транзакцию когда идет целый ряд событий как результат одного. К примеру типовая ситуация: заказ от пользователя (оплата-пересчет остатков-информирование).
Отличный вопрос, как раз разбирали его на теме про паттерны микросервисной архитектуры. Если коротко - транзакционность между микросервисами это дорого и сложно, но есть подходы к организации Тут пример ruclips.net/video/ViCD4ERj578/видео.htmlsi=M7WRUakxvd6PIYtH 1. Event sourcing 2. Saga pattern
Если мы говорим на задержку на чтение и обработку сообщения то за счет структуры Kafka сообщение будет проходить быстрее, т.к. там по сути отсутствует умный роутинг и т.д. Но если наша задача выглядит как в зависимости от сложной логики раскидать сообщение по группам, с какими-нибудь полиси. То тут RabbitMQ будет быстрее так как в Kafka нет внутренних механизмов и все прийдется делать во внешнем сервисе, следовательно только передача сообщения между очередью и сервисом съест львиную долю времени Если суммировать, смотрите на ваш кейс_
Мне кажется автор натягивает сову на глобус говоря, что RabbitMQ это про Push. Сам брокер не знает адреса потребителей, они к нему подключаются и запрашивают новые сообщения. Это только запутывает
Действительно это может немного смущать что rabbitmq ориентирован на push based. В нем есть два типа API push & pull но в большинстве случаев используется push подход (www.rabbitmq.com/docs/consumers#subscribing )
Действительно в самых простых случая очередь можно заменить на реверс + LB Но это только часть функциональности, очереди так же: - Автоматически масштабируются при добавлении и удалении нод из кластера - Могут гарантировать транзакционность и использовать различные стратегии доставки - Часть из очередей могут использоваться в виде хранилища events в event-driven архитектуре - Так же поверх них удобно строить real-time стримы данных и событий и не переживать за то что какой-то из consumer упадет Важно посмотреть на кейс и уже после решать нужна ли очередь или нет
@@digital_train - Балансировщик тоже может добавлять и удалять ноды - Если пользователь не получает ответ в течении 30 секунд, то в большинстве случаев он перестает его ждать и уходит. Поэтому нет смысла накапливать сообщения в надежде когда-то там обработать все. - Событийная архитектура усложняет разработку, если система не помещается на сервер, то лучше использовать шардирование, а не разбиение на подсистемы, что связаны событиями. - После падения консюмеров забивается и падает очередь, что делает ее бессмысленной для спасения. Проще разруливать падение на клиенте путем повторных запросов.
Есть задачи, в которых поток запросов имеет ярко выраженные короткие пики, а в остальное время почти ноль. В этих случаях, если время ответа некритично или ответ вообще не предусмотрен, очередь очень помогает дешево разгрузить обработчики.



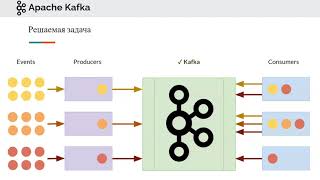






Самое подробнное видео в интернете. И не только в ру сегменте
Спасибо. Отличная подача материала. Можно в том числе слушать фоном параллельно с какими то делами - воспринимается хорошо.
спасибо!
автор прошел в миллиметре от утверждения что в кафке нет acnowledgment
однако, прошел, лайк:)
Доступно. Понятно. Без воды. Лайк. Подписка.
Спасибо. За полчаса всё по полочкам разложил
Отличное представление информации. Просто огонь! Спасибо
Большое спасибо за видео. Понятно и доступно)
Спасибо. Еще бы добавить nats/nats streaming.
Топ контент! Спасибо
Классное видео! Спасибо!
спасибо!!!
Спасибо.
Про multi stage pipeline очень вскользь сказано, хотелось бы на конкретном примере. Например как организовать транзакцию когда идет целый ряд событий как результат одного. К примеру типовая ситуация: заказ от пользователя (оплата-пересчет остатков-информирование).
Отличный вопрос, как раз разбирали его на теме про паттерны микросервисной архитектуры.
Если коротко - транзакционность между микросервисами это дорого и сложно, но есть подходы к организации
Тут пример ruclips.net/video/ViCD4ERj578/видео.htmlsi=M7WRUakxvd6PIYtH
1. Event sourcing
2. Saga pattern
Я правильно понимаю что у Rabbit должны быть ниже задержки, чем у Kafka?
Если мы говорим на задержку на чтение и обработку сообщения то за счет структуры Kafka сообщение будет проходить быстрее, т.к. там по сути отсутствует умный роутинг и т.д.
Но если наша задача выглядит как в зависимости от сложной логики раскидать сообщение по группам, с какими-нибудь полиси. То тут RabbitMQ будет быстрее так как в Kafka нет внутренних механизмов и все прийдется делать во внешнем сервисе, следовательно только передача сообщения между очередью и сервисом съест львиную долю времени
Если суммировать, смотрите на ваш кейс_
Мне кажется автор натягивает сову на глобус говоря, что RabbitMQ это про Push. Сам брокер не знает адреса потребителей, они к нему подключаются и запрашивают новые сообщения. Это только запутывает
Действительно это может немного смущать что rabbitmq ориентирован на push based. В нем есть два типа API push & pull но в большинстве случаев используется push подход (www.rabbitmq.com/docs/consumers#subscribing )
Очереди сообщений не нужны практически никогда! Для этого есть обратный прокси и балансировщик nginx/Apache.
Действительно в самых простых случая очередь можно заменить на реверс + LB
Но это только часть функциональности, очереди так же:
- Автоматически масштабируются при добавлении и удалении нод из кластера
- Могут гарантировать транзакционность и использовать различные стратегии доставки
- Часть из очередей могут использоваться в виде хранилища events в event-driven архитектуре
- Так же поверх них удобно строить real-time стримы данных и событий и не переживать за то что какой-то из consumer упадет
Важно посмотреть на кейс и уже после решать нужна ли очередь или нет
@@digital_train - Балансировщик тоже может добавлять и удалять ноды
- Если пользователь не получает ответ в течении 30 секунд, то в большинстве случаев он перестает его ждать и уходит. Поэтому нет смысла накапливать сообщения в надежде когда-то там обработать все.
- Событийная архитектура усложняет разработку, если система не помещается на сервер, то лучше использовать шардирование, а не разбиение на подсистемы, что связаны событиями.
- После падения консюмеров забивается и падает очередь, что делает ее бессмысленной для спасения. Проще разруливать падение на клиенте путем повторных запросов.
Есть задачи, в которых поток запросов имеет ярко выраженные короткие пики, а в остальное время почти ноль. В этих случаях, если время ответа некритично или ответ вообще не предусмотрен, очередь очень помогает дешево разгрузить обработчики.