Very nice vid! Great job explaining something this complex in 5 mins! A minor note is that S3 clients don't know about the topology behind the scenes, so it is not the client, but "something" in between. For MinIO it is the server itself that does the hash and reaches out to the nodes with the data and collects it to serve the request. But the principle is exactly as you described! (I work @ MinIO) Having the requester know the remote host topology makes the clients more complex, and also makes serving via reverse proxy/load balancing hard. But of course you avoid a forwarding hop, so pros and cons. Memcached, Aerospike does this for example.
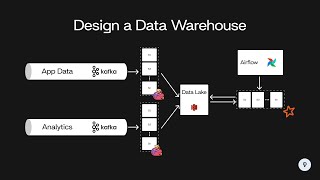
So the BLOB system assume every node have the exact same storage capacity ? Does it do rehashing if a node is already full and cant accept more data ? What happen if a node or multiple nodes are down ? What happen if a node have too many connections for reads ? Do the network congest or does it load balance in a specific way ? Are the reads cached somewhere if some datas are way more accessed than others ? If multiple clients fetch the same data at approximatively the same time (in the same window of time), are both queries optimized to use less ressources together ?
What you said is not correct for MinIO. MinIO features a data sharding concept that splits files into specified parts and stores each part on a separate drive.









Very nice vid! Great job explaining something this complex in 5 mins!
A minor note is that S3 clients don't know about the topology behind the scenes, so it is not the client, but "something" in between. For MinIO it is the server itself that does the hash and reaches out to the nodes with the data and collects it to serve the request. But the principle is exactly as you described! (I work @ MinIO)
Having the requester know the remote host topology makes the clients more complex, and also makes serving via reverse proxy/load balancing hard. But of course you avoid a forwarding hop, so pros and cons. Memcached, Aerospike does this for example.
Yes--thanks for pointing out this nuance!
So the BLOB system assume every node have the exact same storage capacity ?
Does it do rehashing if a node is already full and cant accept more data ?
What happen if a node or multiple nodes are down ?
What happen if a node have too many connections for reads ? Do the network congest or does it load balance in a specific way ?
Are the reads cached somewhere if some datas are way more accessed than others ?
If multiple clients fetch the same data at approximatively the same time (in the same window of time), are both queries optimized to use less ressources together ?
If you want to learn more about these edge cases, check out our full video on interviewpen.com :D
It would be cool to have a video on design of url shortener
We have one, check out our systems end-to-end course on interviewpen.com!
which whitebaording software do you use?
We use GoodNotes on an iPad. Thanks!
What you said is not correct for MinIO. MinIO features a data sharding concept that splits files into specified parts and stores each part on a separate drive.
Yep, we're not going into detail on erasure coding in this video, but we have content on this on interviewpen.com :)