Happy you liked it! I just saw your tweet as well. Feel free to get in contact if you'd like to hop on a video call for a short interview to post on the channel
Hi @ironjr - I loved the paper. @tunadorable did a great job with explaining it too. It feels like this is a significant find. I really want to see if applying grokfast adaptively as suggested could just be a generally good idea. The examples suggest that this could work on pretty broad problems. I may end up testing this myself later tonight, but I want to get your thoughts Jaerin!
@ironjr Low pass filters can be easily implemented using a simple ODE and don't require keeping any history. When designing filters one has flexibility with regard to filter order and so on. Is there a reason why don't implement a construction for arbitrary filters? Do you think an adaptive filtering approach (in particular: the further the training accuracy lacks behind the validation accuracy the more high frequencies are filtered) could be interesting? Also can you distinguish the effect of increasing weight decay and lowpass filtering the gradients of the overfitted network? Does that tell us something interesting?
@ironjr thx for this amazing work! Cant wait to try replicating this on a bit bigger LLMs. Would you say the suggested ranges for hyperparams should stay the same?
it's smart but not simple lol it took many researchers in many years of deep learning experiments with the grokking phenomenon to come up with the idea 😅
what exactly do you mean by this interpretation? would something as simple as: range = max(gradients) - min(gradients); adjustedGradient = sign(gradients[i]) * ((abs(gradients[i] / range) - 0.5) ^ 2 + 0.5) * range; weight -= 0.01 * adjustedGradient; work? or is there a more complex idea behind the comment?
seems i've misunderstood what you meant, it's the error variance in the time dimension. though i think my thing can be rotated, but then it will probably take more memory. i'll try it next though.
the marvelous thing about it is the perceived simplicity, yet no body could come up with this until these gentlemen had this bright idea! everything is hard until someone solves it and then the masses wonder why this seemingly simple thing! has not yet been solved by them before also sometimes, the building blocks had to be layed down for others to come to a specific conclusion/understanding, this is one of those examples as well. still lovely work both in previous papers and this one concerning grokking!
Viewing this as an electrical engineer with some knowledge about signal processing, it seems like the next intuitive step is to implement a Biquad-IIR-Filter with per parameter(-group)-tunable frequency cut-off for a given architecture. It takes more memory again, as an IIR-filter has more state again, but the frequency response is much more controllable than an EMA. For example implementing a Low-Shelf-Filter is exactly what is needed here. This paper basically went from FIR-Filtering (a MA is a very stupid FIR-filter choice) to an IIR-Filter structure which is more memory efficient while preserving the frequency behavior of a MA. I suggest to make the IIR-Filter more complex again and go from first order to 2nd order or even concatenating 2 Biquads to get a 4th order response. I also wonder if this applies to gradient-solvers in general or if this a NN-specific optimization. For example, does it help a least-suqare-function-fitter too, or can it help a solver for the sparse matrices of FEM-problems? I wish you would have explained the "Groking" more, as I basically still dont know what it is, and the paper's explanation is way too targeted at an audience with a certain knowledge base and googling did not help much either.
here’s a tiktok explaining it www.tiktok.com/t/ZPRE8S1eS/ and i can’t understand what you said but ill also mention the author so that they see this @ironjr
That tiktok is a pretty good explanation! I think the one important point that might be missed is that "Grok/Grokking" comes from Heinlein's 1961 book, Stranger in a Strange Land, where it is used as a Martian term for "to understand intuitively or deep understanding". Yea, I didn't get it until I understood that little bit. Basically once the model has trained far beyond the normal amount, it can "sometimes" reach this point of grokking where it gets an emergent deep understanding. The sad part tho, is that this phenomena, at least so far, is not applicable to general learning, but rather very specific algorithms... like the Modulus algorithm, at least from what I have read so far. It is one of the reasons why I tend to ignore "grokking" titles in videos, but I wanted to see what this paper was about! It seems pretty good, tho, without a general application, I am not sure when it can be used since over training is likely to be very expensive, and if there's not a usable "grokking" to come about,. then you are just wasting cycles.
I've left similar explanations in other comments: it's nowhere near certain yet but given the fact that grokking can be induced in non-synthetic datasets (such as MNIST & IMDB sentiment classification displayed in this paper), the current speculation is that in these synthetic datasets it's just easier to see grokking since they only cover a *single* skill/algorithm, where as in something like language modeling there are *many* skills/algorithms to be learned. If true, that would mean that in LLM loss curves the grokking effect becomes invisible since you've got so many tiny sub-skills continuously grokking that they get lossed in the average and give you a seemingly smooth loss curve with only a slight delay, and that this phenomenon would explain why we have smooth loss curves and yet sudden emergence of individual skills on benchmarks
@@Tunadorable Thanks for your insight. It would be interesting to test this process on a highly focused Domain Specific Language Model, where it might be possible to see Grokking for specific training (something bigger than IMDb but still small enough to see those effects).
If im not wrong, I think this is the same principle as Heavy Ball Momentum, where the moving average of the gradient (which can be seen as a low pass filter) can continue to grow and amplify if continually in the same direction
If training gets efficient enough. I can foresee mini training cycles between user prompts could allow models to internalize their interactions. And allow them to actively become specialized toward helping a user.
If someone asked my what "Grokking" was before I saw this video I would have assumed it was some teenage slang meaning something like "wearing a piece of Salad on your head and attracting all the girls" but I seem to not only fall out of style with the youth but also with the recent trends in tech.. I get old..
5:23, given this definition, I thought we've been doing this the whole time. I was under the impression we used small batches due to hardware limitations, and each epoch it adjusts the weights based on all the batches combined. Would using a massive batch size achieve the same effect?
Wait, I'm confused. If you're just holding an exponential moving average in memory and adding it to the gradient, how is that different from, like, regular inertia?
grokfast is taking the momentum of grads similar to that of AdamW, if you try AdamW on the same tasks, it mitigates grokking almost as well as grokfast
@@lukeskywalker7029 like do we just need slow gradient with jiggle, or do the specific fast gradients from the training batch help. If we just need slow gradient and jiggle maybe we can learn much faster than we have been
Could be a cool way to get out from global minima? Once converged, run few thousand noise-trials to see if one of them leads to a path for an even lower loss dip
My guyyyy. You’re too real for this 😂. Yea ways around the memory tibits, ternary LM’s are the future and few other tricks makes this less of a problem. Data quality is just as important, like extremely important, hybrid data is the future(“Grokked Transformers are Implicit Reasoners” empirically prove this), people called me looney but I was like raw data is way too oblique, but we must figure out a derivative of MLE that’s optimized for model collapse, completely solvable….but I stand on it. Paper of the year 😂. People are sleeping. Deeper models are actually more susceptible to grokking, but the compute needed is an issue, this may be the solution. A super cheap POWERFUL hobbling as the kids say. Research like this will allow smaller labs/startups to compete with the big guys. Compositional generalization is within reach.
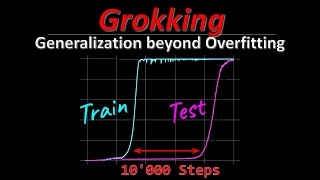
Apologies to the authors, as I realize that my comment might sound a little harsh. I am sure the research is well founded. But, isn't Grokking a super niche emergent effect that doesn't really apply generally to LLM, but only under very specific circumstances, such as very specific math algorithms? I guess to me, this type of research really needs a proof that it can be applied more generally, before it will have significant utility. When I first started to see "grokking", it was quite the buzz word, but the more I learn about it the less excited I am. I can see the allure, just keep training far beyond normal and "eventually" your model learns something. But it sounds to me like this is a carrot that will never be able to applied without a very specific set of data and specific training requirements. Until they can find some more general application, I see very little utility in spending that much more extra time to over train, just to find out that the Grokking isn't going to work unless it is some esoteric math function that no one will actually use for a real application. (But, if I have it wrong, then I apologize). Edit: I guess since it does show some efficacy in the IMDb sentiment classification. So, perhaps I was too hasty in my earlier comment. I think I had trouble deciphering the graph for the IMDb, with the overlapping colors for raw and EMA.
perfectly fine critique. my impression right now is that grokking is visible on those single synthetic math tasks specifically because they are *single* tasks that the model is being trained on, in contrast to LLMs which have to do *many* tasks. speculation in the field right now is that grokking may in fact happen at the level of individual tasks within an LLM, but there are so many tasks in there that everything ends up averaging out and we get only a marginal if not invisible delay in test accuracy. after all, in this paper they also trained an MNIST classifier and an IMDB sentiment analysis model which, while by no means are they as complicated as an LLM, certainly are examples of real data with multiple tasks that still experience grokking and can have that grokking corrected / sped up by this method
i meant to add that if this speculation about LLMs is in fact true, then it would mean that grokking is an explanation for sudden skill emergence despite smooth loss curves
@@Tunadorable Ah, valid points, tho memory might be a issue with larger data sets. I recall that selective State Space models seems to be more efficient with memory, but, I haven't seen anything about Grokking for those. If you happen to come by anything... it might be worth a review.
We've gotta do what we can, if it's possible to see improvements gained from a novel approach to a niche problem then it might be possible to amplify that solution in some way to where it generalizes better.
I wonder whether the EMA approach would allow for second order training methods with small batch sizes to work well. Would be awesome to try L-BFGS with EMA and small batches in micro GPT sandbox!
working on an update to the templateGPT thing right now to put it more in line with karpathy’s latest video (meaning it’ll be more efficient & also capable of training ~100m parameter models on a gpu cluster) and i’m gonna include this grokfast-EMA thing as an optional add-on that you can toggle in the settings
@@Tunadorable Nice. I've been playing with it on a 3090 and can train up to ~50m somewhat reasonably on that with it. It definitely doesn't support L-BFGS as is though and some of the unusual models like future former apparently store some tensors on the CPU which leads to a failure so I have to turn GPU off
yes i’ve not yet got FutureFormer working, hoping to refactor it after i finish the current templateGPT edits. excited to hear someone is actually using these😁
I wish I had been doing so from the beginning. Eventually I plan to open-source all the pdf highlights & notes in my notes app but we're not quite there yet. For now you can check out the file `papers_kept.csv` in this repo to see a list of all the papers that I plan to read which gets updated every week (first week was last week) github.com/evintunador/arxiv-summaries-workflow
You might try searching on GitHub. However the code I linked to is simple enough that you could copy & paste it into chatGPT or Claude 3.5 and ask it to translate from pytorch to tensor flow and I'd bet the latter especially could get it right first try
EWA seems kinda obvious, no? That's the best estimate for a signal that is signal + noise. Would've thought that's already included in Adam and the like, with all the complicated momentum terms .
Blah Blah Blah..... LSTM FAST-GROKKING? Hell Yeah! Great info. I get excited looking back at things "b4 transformers" simply because they cannot and are not the end all - be all in pretraining. I especially love LSTM (xLSTM and this lately piqued my interest) variants surrounding music and action (task,scene, whatever - just please, not another stock algo) prediction/suggestion (Is your film "too" predictable?).
This is probably a silly question but can someone explain to me how the technique of Grokking and the ai hardware company known as Groq both came up with the same phonetically sounding names? Is it as simple as someone within Groq capitalizing on the word Grok(king)? Just very curious. not looking for conspiracies, just probable reasons.
not sure how Groq chose their name, but the original term “grokking” was coined by a 1961 sci fi author where he defined it as “to understand deeply” and the model training behavior that was named after that sci fi author’s term was discovered by researchers at Apple
Awesome! Fits well with the recent ANU researchers who demonstrated that you can induce grokking in arbitrary systems by overparameterizing and the notion is model agnostic. Video here ruclips.net/video/UBjgSfWa2tw/видео.htmlsi=T6cjE8f0UENxLqSr
The code can certainly be dropped in & used on a CNN or RNN but they did not test it in this paper, so results may vary. In theory there's no reason why it wouldn't also work there just as well
2:28 - thanks to it being a logarithmic scale, you can - for once - actually say that it is an order of magnitude faster. because it is (actually) an order of magnitude faster, which is pretty significant, yes
To my memory they tested three tasks/datasets in this paper of reasonably wide variety (synthetic math, image classification, and language sentiment analysis) but as with all science, we won't know if / how well it works with others until somebody tests it out and publishes
At this point we arent going ahead without this so anything that can improve scaling and training is super important to replace humans with intelligent life.
@Tunadorable The fake ai apocalypse is going to be hilarious. When Trump is elected again he spends so much money on fake ai to throw people in jail. Its like Hitler with less charisma.
so i’m not an optimizer person but they clarified this toward the end. to the best of my memory they said that rather than being momentum on the parameter movement its momentum on the gradient itself, which is somehow slightly different. i could be getting fooled on this tho, like i said optimizers are not my thing
Looks to me like if there is a significant difference, it's the adjustable window size and application of a low pass filter to several previous steps at once, whereas AdamW has to rely on two moments to represent the entire past.
momentum takes average of the past and present (in which present counts very little, few percent) and grokfast uses present momentu and adds a bit of the average of the past to it, so the present gradient counts 100% and is just a little bit redirected by the past ones
As this paper mentions it's been shown on MNIST and IMDB sentiment analysis, and to the best of my memory the first paper that explored those two datasets found a reliable phase-shift between good training, grokking, and divergence when they did a grid search over multiple different hyper parameters (weight decay and learning rate to the best of my memory). IF it's happening in LLMs the thought is that they have so many tasks (these synthetic datasets are each only one "task") that each individual grok occurrence ends up averaging out and it becomes invisible in the loss curves, but it does constitute a possible explanation for sudden skill emergence despite smooth loss curves
Current training sequences are incredibly inefficient. Think about how little data we as humans consume to get to our intelligence. Many many orders of magnitude less data than these models.
I've heard this argument before but I've gotta disagree because it's always framed in the lens of one single modality. Sure if you compare the amount of language an LLM has trained on to the amount of language a 5 year old has heard there's no comparison, the 5 year old looks more efficient. But in reality the 5 year old was also taking in extremely high resolution vision, stereo audio, touch, taste, smell, and proprioception every millisecond of being awake since being born. I saw a tweet awhile ago, I think by Yann Lecunn but I could be misremembering, that tried to estimate how much multimodal data a 5 year old has taken in and the low estimate completely blew out of the water our current 15T token LLMs. That plus the human brain like all animal brains is pre-wired with certain phenomena already innately known, such as a fear of snakes, whereas neural networks are randomly initialized. That being said I do agree with you that current training strategies are likely massively inefficient compared to what we'll have in the future
@@Tunadorable the vast majority of data humans intake is immediately lost due to attention mechanisms, and then further pruned during sleep cycles. Contrast the amount of visual information taken in by your eyes every second, and then think back to the last time you were in a car. How much of that trip do you remember? How many red lights vs green lights?
Humans are purely analog machines. We don't have limited word lengths or an instruction set abstraction between training models and the actual silicon doing the math.
The whole concept of high vs low frequency gradients makes me think of training wheels on a bicycle. Initially, you need the harsh feedback of the training wheels until eventually you are able to maintain balance with finer internalized corrections.






![BLACK BAG - Official Trailer [HD] - Only in Theaters March 14](http://i.ytimg.com/vi/Du0Xp8WX_7I/mqdefault.jpg)
![Noob To Max With DRAGON REWORK In Blox Fruits [FULL MOVIE]](http://i.ytimg.com/vi/LnBMOinoOvA/mqdefault.jpg)

Author here! Happy to have this wonderful introduction. Huge thanks for reviewing our work! Your explanation looks way better than mine 😂.
Happy you liked it! I just saw your tweet as well. Feel free to get in contact if you'd like to hop on a video call for a short interview to post on the channel
Hi @ironjr - I loved the paper. @tunadorable did a great job with explaining it too. It feels like this is a significant find.
I really want to see if applying grokfast adaptively as suggested could just be a generally good idea. The examples suggest that this could work on pretty broad problems. I may end up testing this myself later tonight, but I want to get your thoughts Jaerin!
@ironjr Low pass filters can be easily implemented using a simple ODE and don't require keeping any history. When designing filters one has flexibility with regard to filter order and so on. Is there a reason why don't implement a construction for arbitrary filters?
Do you think an adaptive filtering approach (in particular: the further the training accuracy lacks behind the validation accuracy the more high frequencies are filtered) could be interesting?
Also can you distinguish the effect of increasing weight decay and lowpass filtering the gradients of the overfitted network? Does that tell us something interesting?
Your paper is impressive and well written. Can't wait to test the approach in action.
@ironjr thx for this amazing work! Cant wait to try replicating this on a bit bigger LLMs. Would you say the suggested ranges for hyperparams should stay the same?
What a smart and simple idea! Just adjust down big errors and adjust up small errors. This keeps the weights from jumping around.
it's smart but not simple lol it took many researchers in many years of deep learning experiments with the grokking phenomenon to come up with the idea 😅
what exactly do you mean by this interpretation? would something as simple as:
range = max(gradients) - min(gradients);
adjustedGradient = sign(gradients[i]) * ((abs(gradients[i] / range) - 0.5) ^ 2 + 0.5) * range;
weight -= 0.01 * adjustedGradient;
work? or is there a more complex idea behind the comment?
seems i've misunderstood what you meant, it's the error variance in the time dimension. though i think my thing can be rotated, but then it will probably take more memory. i'll try it next though.
the marvelous thing about it is the perceived simplicity, yet no body could come up with this until these gentlemen had this bright idea!
everything is hard until someone solves it and then the masses wonder why this seemingly simple thing! has not yet been solved by them before
also sometimes, the building blocks had to be layed down for others to come to a specific conclusion/understanding, this is one of those examples as well.
still lovely work both in previous papers and this one concerning grokking!
Viewing this as an electrical engineer with some knowledge about signal processing, it seems like the next intuitive step is to implement a Biquad-IIR-Filter with per parameter(-group)-tunable frequency cut-off for a given architecture. It takes more memory again, as an IIR-filter has more state again, but the frequency response is much more controllable than an EMA. For example implementing a Low-Shelf-Filter is exactly what is needed here. This paper basically went from FIR-Filtering (a MA is a very stupid FIR-filter choice) to an IIR-Filter structure which is more memory efficient while preserving the frequency behavior of a MA. I suggest to make the IIR-Filter more complex again and go from first order to 2nd order or even concatenating 2 Biquads to get a 4th order response.
I also wonder if this applies to gradient-solvers in general or if this a NN-specific optimization. For example, does it help a least-suqare-function-fitter too, or can it help a solver for the sparse matrices of FEM-problems?
I wish you would have explained the "Groking" more, as I basically still dont know what it is, and the paper's explanation is way too targeted at an audience with a certain knowledge base and googling did not help much either.
here’s a tiktok explaining it
www.tiktok.com/t/ZPRE8S1eS/
and i can’t understand what you said but ill also mention the author so that they see this @ironjr
That tiktok is a pretty good explanation! I think the one important point that might be missed is that "Grok/Grokking" comes from Heinlein's 1961 book, Stranger in a Strange Land, where it is used as a Martian term for "to understand intuitively or deep understanding". Yea, I didn't get it until I understood that little bit. Basically once the model has trained far beyond the normal amount, it can "sometimes" reach this point of grokking where it gets an emergent deep understanding. The sad part tho, is that this phenomena, at least so far, is not applicable to general learning, but rather very specific algorithms... like the Modulus algorithm, at least from what I have read so far. It is one of the reasons why I tend to ignore "grokking" titles in videos, but I wanted to see what this paper was about! It seems pretty good, tho, without a general application, I am not sure when it can be used since over training is likely to be very expensive, and if there's not a usable "grokking" to come about,. then you are just wasting cycles.
I've left similar explanations in other comments: it's nowhere near certain yet but given the fact that grokking can be induced in non-synthetic datasets (such as MNIST & IMDB sentiment classification displayed in this paper), the current speculation is that in these synthetic datasets it's just easier to see grokking since they only cover a *single* skill/algorithm, where as in something like language modeling there are *many* skills/algorithms to be learned. If true, that would mean that in LLM loss curves the grokking effect becomes invisible since you've got so many tiny sub-skills continuously grokking that they get lossed in the average and give you a seemingly smooth loss curve with only a slight delay, and that this phenomenon would explain why we have smooth loss curves and yet sudden emergence of individual skills on benchmarks
@@Tunadorable Thanks for your insight. It would be interesting to test this process on a highly focused Domain Specific Language Model, where it might be possible to see Grokking for specific training (something bigger than IMDb but still small enough to see those effects).
Thank you guys so much for the productive comments! That TikTok was all I needed. Super cool.
If im not wrong, I think this is the same principle as Heavy Ball Momentum, where the moving average of the gradient (which can be seen as a low pass filter) can continue to grow and amplify if continually in the same direction
Simply put: You want to make the slow learning faster, so you just make it faster.
Isn't this essentially like momentum way back in the day?
If training gets efficient enough. I can foresee mini training cycles between user prompts could allow models to internalize their interactions. And allow them to actively become specialized toward helping a user.
already venturing into that with a few use cases 7 clients!
If someone asked my what "Grokking" was before I saw this video I would have assumed it was some teenage slang meaning something like "wearing a piece of Salad on your head and attracting all the girls" but I seem to not only fall out of style with the youth but also with the recent trends in tech.. I get old..
"grok" comes from the sci fi book Stranger in strange Land
Very impressed by this overview.
5:23, given this definition, I thought we've been doing this the whole time. I was under the impression we used small batches due to hardware limitations, and each epoch it adjusts the weights based on all the batches combined. Would using a massive batch size achieve the same effect?
Wait, I'm confused. If you're just holding an exponential moving average in memory and adding it to the gradient, how is that different from, like, regular inertia?
Exactly my thoughts. Sounds like a double momentum
grokfast is taking the momentum of grads similar to that of AdamW, if you try AdamW on the same tasks, it mitigates grokking almost as well as grokfast
Replacing the high frequency gradients with different types of noise would be interesting
What do you think could be the benefit of re-adding white, pink or some other noise spectrum? Dont really get the intuition...
@@lukeskywalker7029 like do we just need slow gradient with jiggle, or do the specific fast gradients from the training batch help. If we just need slow gradient and jiggle maybe we can learn much faster than we have been
@@graham8316 can you give me a python or even better triton implementation for that? Then ill test it out ;)
Perhaps use something inspired by dropout?
Could be a cool way to get out from global minima? Once converged, run few thousand noise-trials to see if one of them leads to a path for an even lower loss dip
My guyyyy. You’re too real for this 😂. Yea ways around the memory tibits, ternary LM’s are the future and few other tricks makes this less of a problem. Data quality is just as important, like extremely important, hybrid data is the future(“Grokked Transformers are Implicit Reasoners” empirically prove this), people called me looney but I was like raw data is way too oblique, but we must figure out a derivative of MLE that’s optimized for model collapse, completely solvable….but I stand on it. Paper of the year 😂. People are sleeping. Deeper models are actually more susceptible to grokking, but the compute needed is an issue, this may be the solution. A super cheap POWERFUL hobbling as the kids say. Research like this will allow smaller labs/startups to compete with the big guys. Compositional generalization is within reach.
With mechinterp upsides eh?
Like update momentum, but taking an average instead of using geometric decay?
How is this any different from stochastic average gradient (SAG) methods?
Thank you so much for highlighting tools like this! Keep it up!
Thankyou for breakdown. As a non-machine learning person this was really interesting and seems ground breaking.
Nice Hunter S Thompson look!
Love your videos man keep it up, cant believe I found you on accident never looked back
Apologies to the authors, as I realize that my comment might sound a little harsh. I am sure the research is well founded. But, isn't Grokking a super niche emergent effect that doesn't really apply generally to LLM, but only under very specific circumstances, such as very specific math algorithms? I guess to me, this type of research really needs a proof that it can be applied more generally, before it will have significant utility.
When I first started to see "grokking", it was quite the buzz word, but the more I learn about it the less excited I am. I can see the allure, just keep training far beyond normal and "eventually" your model learns something. But it sounds to me like this is a carrot that will never be able to applied without a very specific set of data and specific training requirements. Until they can find some more general application, I see very little utility in spending that much more extra time to over train, just to find out that the Grokking isn't going to work unless it is some esoteric math function that no one will actually use for a real application. (But, if I have it wrong, then I apologize).
Edit: I guess since it does show some efficacy in the IMDb sentiment classification. So, perhaps I was too hasty in my earlier comment. I think I had trouble deciphering the graph for the IMDb, with the overlapping colors for raw and EMA.
perfectly fine critique. my impression right now is that grokking is visible on those single synthetic math tasks specifically because they are *single* tasks that the model is being trained on, in contrast to LLMs which have to do *many* tasks. speculation in the field right now is that grokking may in fact happen at the level of individual tasks within an LLM, but there are so many tasks in there that everything ends up averaging out and we get only a marginal if not invisible delay in test accuracy. after all, in this paper they also trained an MNIST classifier and an IMDB sentiment analysis model which, while by no means are they as complicated as an LLM, certainly are examples of real data with multiple tasks that still experience grokking and can have that grokking corrected / sped up by this method
i meant to add that if this speculation about LLMs is in fact true, then it would mean that grokking is an explanation for sudden skill emergence despite smooth loss curves
@@Tunadorable Ah, valid points, tho memory might be a issue with larger data sets. I recall that selective State Space models seems to be more efficient with memory, but, I haven't seen anything about Grokking for those. If you happen to come by anything... it might be worth a review.
to the best of my memory that's exactly the process that this paper was describing
ruclips.net/video/ONt9s7D-rJ4/видео.html
We've gotta do what we can, if it's possible to see improvements gained from a novel approach to a niche problem then it might be possible to amplify that solution in some way to where it generalizes better.
Memorization is quick. Understanding is slow using lower level reasoning and maths circuits
I wonder whether the EMA approach would allow for second order training methods with small batch sizes to work well. Would be awesome to try L-BFGS with EMA and small batches in micro GPT sandbox!
working on an update to the templateGPT thing right now to put it more in line with karpathy’s latest video (meaning it’ll be more efficient & also capable of training ~100m parameter models on a gpu cluster) and i’m gonna include this grokfast-EMA thing as an optional add-on that you can toggle in the settings
@@Tunadorable Nice. I've been playing with it on a 3090 and can train up to ~50m somewhat reasonably on that with it. It definitely doesn't support L-BFGS as is though and some of the unusual models like future former apparently store some tensors on the CPU which leads to a failure so I have to turn GPU off
yes i’ve not yet got FutureFormer working, hoping to refactor it after i finish the current templateGPT edits. excited to hear someone is actually using these😁
Do you maintain some kind of list of topics and papers you've been working through by any chance?
I wish I had been doing so from the beginning. Eventually I plan to open-source all the pdf highlights & notes in my notes app but we're not quite there yet. For now you can check out the file `papers_kept.csv` in this repo to see a list of all the papers that I plan to read which gets updated every week (first week was last week)
github.com/evintunador/arxiv-summaries-workflow
Will try out this optimizer when I get to work, curious to see how it does vs. classic Adam
Please keep us up to date with any applications of grokfast and whether or not it improved performance for you 😊
Is there an implementation for tensorflow? I am new to machine learning and I am familiar only with tensorflow.
You might try searching on GitHub. However the code I linked to is simple enough that you could copy & paste it into chatGPT or Claude 3.5 and ask it to translate from pytorch to tensor flow and I'd bet the latter especially could get it right first try
@@Tunadorable I am going to try that !
EWA seems kinda obvious, no? That's the best estimate for a signal that is signal + noise.
Would've thought that's already included in Adam and the like, with all the complicated momentum terms .
I say this cause I've been using EWA and similar variants to model signals in my free time for 4+ years now.
Blah Blah Blah..... LSTM FAST-GROKKING? Hell Yeah! Great info. I get excited looking back at things "b4 transformers" simply because they cannot and are not the end all - be all in pretraining. I especially love LSTM (xLSTM and this lately piqued my interest) variants surrounding music and action (task,scene, whatever - just please, not another stock algo) prediction/suggestion (Is your film "too" predictable?).
This is probably a silly question but can someone explain to me how the technique of Grokking and the ai hardware company known as Groq both came up with the same phonetically sounding names? Is it as simple as someone within Groq capitalizing on the word Grok(king)? Just very curious. not looking for conspiracies, just probable reasons.
not sure how Groq chose their name, but the original term “grokking” was coined by a 1961 sci fi author where he defined it as “to understand deeply” and the model training behavior that was named after that sci fi author’s term was discovered by researchers at Apple
@@Tunadorable Oh nice. I thought it would be too much to ask what grokking actually meant. Thank you, I appreciate this.
Awesome! Fits well with the recent ANU researchers who demonstrated that you can induce grokking in arbitrary systems by overparameterizing and the notion is model agnostic. Video here ruclips.net/video/UBjgSfWa2tw/видео.htmlsi=T6cjE8f0UENxLqSr
can it be applied to (how) to CNNs and RNNs?
The code can certainly be dropped in & used on a CNN or RNN but they did not test it in this paper, so results may vary. In theory there's no reason why it wouldn't also work there just as well
2:28 - thanks to it being a logarithmic scale, you can - for once - actually say that it is an order of magnitude faster.
because it is (actually) an order of magnitude faster, which is pretty significant, yes
what is a basic mental model to interpret all this, or even just grok itself, for a newbie
intuititve metaphor explanation of grokking here: www.tiktok.com/t/ZPREjCckt/
I don't got no tiktoks this is RUclips
Does it applies to other tasks/datasets?
To my memory they tested three tasks/datasets in this paper of reasonably wide variety (synthetic math, image classification, and language sentiment analysis) but as with all science, we won't know if / how well it works with others until somebody tests it out and publishes
At this point we arent going ahead without this so anything that can improve scaling and training is super important to replace humans with intelligent life.
lol
@verigumetin4291 caps like "ai scawy," but humans have committed all known atrocities, and ai has done zero.
i beg to differ, today the walmart self checkout camera AI caught me trying to counteract inflation and i’d count that as a crime against humanity
@Tunadorable The fake ai apocalypse is going to be hilarious. When Trump is elected again he spends so much money on fake ai to throw people in jail. Its like Hitler with less charisma.
where do you publish papers anyway?
i have never published a paper, but 99.9% of the ones i read in these videos come from arxiv.org
@@Tunadorable any idea on what happens to intellectual property for papers published there?
@@wanfuse no clue, but I imagine it'd be the same as any other pre-print website
Isn’t this just momentum?
so i’m not an optimizer person but they clarified this toward the end. to the best of my memory they said that rather than being momentum on the parameter movement its momentum on the gradient itself, which is somehow slightly different. i could be getting fooled on this tho, like i said optimizers are not my thing
Looks to me like if there is a significant difference, it's the adjustable window size and application of a low pass filter to several previous steps at once, whereas AdamW has to rely on two moments to represent the entire past.
Alg 1 is just some weird form of dual averaging, Alg 2 is basically just momentum... nothing new here
momentum takes average of the past and present (in which present counts very little, few percent) and grokfast uses present momentu and adds a bit of the average of the past to it, so the present gradient counts 100% and is just a little bit redirected by the past ones
@@niceshotapps1233 this can be achieved by simply adjusting the momentum parameter
This may be as big as NAGD , ADAM etc.
Nice review of the paper, sub unlocked
"I SKIPPED RIGHT BY IT"
You seem to skip a lot of things, helluva smart young fella.
Thanks a lot that was very interesting!
Anyone find it interesting that grokking only works reliably on synthetic data?
As this paper mentions it's been shown on MNIST and IMDB sentiment analysis, and to the best of my memory the first paper that explored those two datasets found a reliable phase-shift between good training, grokking, and divergence when they did a grid search over multiple different hyper parameters (weight decay and learning rate to the best of my memory). IF it's happening in LLMs the thought is that they have so many tasks (these synthetic datasets are each only one "task") that each individual grok occurrence ends up averaging out and it becomes invisible in the loss curves, but it does constitute a possible explanation for sudden skill emergence despite smooth loss curves
Current training sequences are incredibly inefficient. Think about how little data we as humans consume to get to our intelligence. Many many orders of magnitude less data than these models.
I've heard this argument before but I've gotta disagree because it's always framed in the lens of one single modality. Sure if you compare the amount of language an LLM has trained on to the amount of language a 5 year old has heard there's no comparison, the 5 year old looks more efficient. But in reality the 5 year old was also taking in extremely high resolution vision, stereo audio, touch, taste, smell, and proprioception every millisecond of being awake since being born. I saw a tweet awhile ago, I think by Yann Lecunn but I could be misremembering, that tried to estimate how much multimodal data a 5 year old has taken in and the low estimate completely blew out of the water our current 15T token LLMs. That plus the human brain like all animal brains is pre-wired with certain phenomena already innately known, such as a fear of snakes, whereas neural networks are randomly initialized. That being said I do agree with you that current training strategies are likely massively inefficient compared to what we'll have in the future
@@Tunadorable the vast majority of data humans intake is immediately lost due to attention mechanisms, and then further pruned during sleep cycles. Contrast the amount of visual information taken in by your eyes every second, and then think back to the last time you were in a car. How much of that trip do you remember? How many red lights vs green lights?
Humans are purely analog machines. We don't have limited word lengths or an instruction set abstraction between training models and the actual silicon doing the math.
The whole concept of high vs low frequency gradients makes me think of training wheels on a bicycle. Initially, you need the harsh feedback of the training wheels until eventually you are able to maintain balance with finer internalized corrections.
Nice and thx for the recording, but if You need a banana :-o I will send u one.
Grokking unlocked
Lmao so grokking is enhanced by some kindof low pass filter
Fun fact: If you double tap a comment, the comment gets liked 👍
oi
oi