Can you help me understand how and why are the positional embeddings effective in transformers (vision or text). Can't the model just learn that through its existing weights. How does adding extra positional embeddings to the vision/text embeddings help? Even if we have a unique vector for each position, when we add those to the text embeddings the result won't be unique. Would the result after addition even have useful information, since we can get same addition values from multiple combinations. Let's say we have a text model that has input limit of only two tokens. and the embedding size is 3. Text embeddings: [0, 1.1, 0.3], [0, 0.1,1.3] position embeddings: [0, 0, 1], [0, 1, 0] Embeddings after addition: [0, 1.1, 1.3], [0, 1, 1.3] We get same vectors Is the magic in the actual function that we use for embeddings or is it just empirically better and we can't understand it fully.
Inside the model, we compute the self-attentions. They are pretty much just a measure of interaction between the different tokens in the input sequence. Inside the attention layer, we have the queries, the keys and the values. The keys and queries are used to compute the self-attentions and the resulting hidden states is the weighted average of the values where we use the attentions as weights. At that point, the order of the tokens in completely lost because we are just summing stuff together without knowing in what order they were before the sum. That is why we keep the position information through the positional encoding. We systematically add the same vector for the same position so the model starts to understand how that shift relates to that position. The value of the same token varies depending on its position. To be fair, we do it a bit differently in 2024. Video coming!
@@TheMLTechLead Looking forward to it! After commenting, I read about RoPE (can't say fully understood it) and learnable positional embeddings. P.S. I really liked your idea of using routing in attention, a bit ambitious goal, but I want to use it to train a small language model or I will see if it is possible to simply add it in a pre-trained model without losing the learned weights.
@@jaskiratbenipal8255 I may not make a video about RoPE but I wrote something about it here: www.linkedin.com/posts/damienbenveniste_most-modern-llms-are-built-using-the-rope-activity-7188571849084096515-mmUk. For the routed self-attentions, I am looking forward to see somebody implementing those and training a model with it.
@@TheMLTechLead I tried it, I trained a language model from scratch for next character prediction (to have small vocabulary). The results were good using normal attention, the model was able to form words and phrases and some jibberish that looked like words. With the routed attention (I tried 0.1 and 0.3 sparcity values), it started to diverge and model was not converging at all after first epoch. The training time did decrease from 34 to 24 mins.









Good job.
Merci pour ton travail. C'est vachement bien ce que tu fais.
Can you help me understand how and why are the positional embeddings effective in transformers (vision or text). Can't the model just learn that through its existing weights. How does adding extra positional embeddings to the vision/text embeddings help? Even if we have a unique vector for each position, when we add those to the text embeddings the result won't be unique. Would the result after addition even have useful information, since we can get same addition values from multiple combinations.
Let's say we have a text model that has input limit of only two tokens. and the embedding size is 3.
Text embeddings:
[0, 1.1, 0.3], [0, 0.1,1.3]
position embeddings:
[0, 0, 1], [0, 1, 0]
Embeddings after addition:
[0, 1.1, 1.3], [0, 1, 1.3]
We get same vectors
Is the magic in the actual function that we use for embeddings or is it just empirically better and we can't understand it fully.
Inside the model, we compute the self-attentions. They are pretty much just a measure of interaction between the different tokens in the input sequence. Inside the attention layer, we have the queries, the keys and the values. The keys and queries are used to compute the self-attentions and the resulting hidden states is the weighted average of the values where we use the attentions as weights. At that point, the order of the tokens in completely lost because we are just summing stuff together without knowing in what order they were before the sum. That is why we keep the position information through the positional encoding. We systematically add the same vector for the same position so the model starts to understand how that shift relates to that position. The value of the same token varies depending on its position. To be fair, we do it a bit differently in 2024.
Video coming!
@@TheMLTechLead Looking forward to it!
After commenting, I read about RoPE (can't say fully understood it) and learnable positional embeddings.
P.S. I really liked your idea of using routing in attention, a bit ambitious goal, but I want to use it to train a small language model or I will see if it is possible to simply add it in a pre-trained model without losing the learned weights.
@@jaskiratbenipal8255 I may not make a video about RoPE but I wrote something about it here: www.linkedin.com/posts/damienbenveniste_most-modern-llms-are-built-using-the-rope-activity-7188571849084096515-mmUk. For the routed self-attentions, I am looking forward to see somebody implementing those and training a model with it.
@@TheMLTechLead I tried it, I trained a language model from scratch for next character prediction (to have small vocabulary). The results were good using normal attention, the model was able to form words and phrases and some jibberish that looked like words. With the routed attention (I tried 0.1 and 0.3 sparcity values), it started to diverge and model was not converging at all after first epoch. The training time did decrease from 34 to 24 mins.
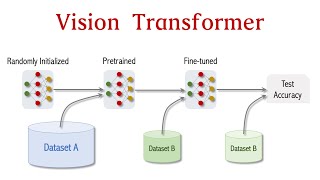
So this is basically used for classification? For example, cat and dogs, right?
It can be used for any computer vision ML task.
@TheMLTechLead great!
I was thinking of image generation for a given prompt or user input.., what would the process be?
Oh no, you would need a very different model for that. Although, the vision transformer can be an element of it.
@@TheMLTechLead got you!