For details and code on building a translator using a transformer neural network, check out my playlist "Transformers from scratch": ruclips.net/video/QCJQG4DuHT0/видео.html
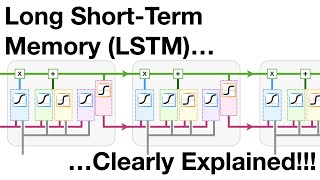
The first time that i see how someone "unrolled" the lstm network and actually demonstrated it. This could not do any professor that i saw. They only showed the picture of cells anybody could find on the internet. Thank you very much, good job!
Programmed my first LSTM with that video. Really good introduction to this topic. Right amount of math, architecture, background (GRU, RNN etc) and coding.
WTF did i just watched....man in 15 min video you explained so many topics and smoothly.....I'm new to AI but what you did was impressive. You explainaid the meaning of everything while simplifieng math concepts BUT STILL putting them in....thank you for your work, I really appreciate it
I’m not done with watching it. But I had to leave a comment first. I think you have really cracked the way to make people understand. Not a single professor has ever taught the way you have unfortunately. I have always wanted someone whose teaching to start from ground up and just explain everything before diving into math. You even explained what os and random was that’s never seen before in cs 😂. So thank you I really enjoy your video it is great for once someone understood a student who might be watching this does not have a phd in mathematics so explaining what each variable means and what the big picture is might save them hours of being lost and confused. Keep up the great work man I really appreciate this channel now it’s a hidden gem!!!!
Hello, have a question: @8:50 you mentioned x(0)... x(n) as inputs. If you had a sentence "Hello World", is a vector of "Hello" be x(0) and "World" be x(1)? If so, x(0) and x(1) will require 2 LSTM cells, and will one line of "model.add(LSTM)" have two LSTM cells to process "Hello World"? How can we visualize more than one LSTM layer then?
Thank you SO MUCH for giving some examples of each architecture. Im following multiple ML courses on uni, but everything is abstracted away behind mathematical jargon, and never gets back to basics.
Can't understand some points. If I have a set of temperature values or closing price of a day. Just one linear sequence. I need to forecast 3 future days values by 10 previous days values. So the question is which of values I need to put into the first LSTM cell, which values into the second cell and so on? The second question is how much LSTM cells I need for this calculations; does an LSTM cells count depend on previous days count or future days count?
Hi! just a question, does lstm predict on sequences of FEATURES in ONE SAMPLE or sequences of SAMPLES (outputs) in ONE BATCH? For eg. I need to predict next number as many to one. I fit first sample as x1=1, x2=2 and output y=3, next sample x1=4, x2=5 y=6. NOW Does the model look on sequence of features (x1,x2) or sequence of samples (y, which are output of the model)
Can you explain further what the hidden size argument is for in the LSTM? Many say it is the dimensionality of the output but I don't get it. The sample explanations of LSTM I saw only has 1 dimensionality so what does it mean when hidden size or number of units as some refer to is more than 1?
Don't BatchNorms and He Initilaization fix Vanishing/Exploding Gradients? ResNet actually fixed model degredation, where deeper models perform worse than smaller models. Deeper networks should learn identity connections if an optimal model has smaller models. The ResNet shortcut connection allows easy learning of mappings similar to identity mappings. How does affect LSTMs? Why can't we just include BatchNorms to fix vanishing/exploding gradients?
Hello! Your Link to your coursera videos is seemingly broken/expired. Can I find videos from you on coursera and can you recommend more learning material like courses and books to me? Thank you! Great videos.
Hi , i need some help here why we decide to make the next hidden state = the long memory after filter it ? why not the next hidden layer not = the long memory (Ct)
Isn't 128 is too many for hidden size? I building an LSTM network, my input shape is [300, 5] and using hidden_size=128 results in gradient vanishing. Also, what happens if I add more layers to the dense net which comes after LSTM? Will this architecture be able to learn? Because LSTM "requires" a relatively large learning rate, which is often too large for typical FC network I am guessing that this will cause some crazy instability as a whole. I hope you could help me with these annoying questions :). Thanks a lot for sharing your knowledge!
If I got the right understanding, since the propagation of weigth should happen throught jumps over d units instead of directly to next one, the explosion problem should happen in a "smoother rate"
I'm new to AI so this might be a silly question but I thought the weights were randomly initialized, how is it possible it performed so well on the first epoch? I assumed the characters would be completely random but they make at least some semblance of words already, or is there already some learning done before the end of the first epoch? Btw thanks so much for the video! Way clearer than others I've watched
@@siddheshbalshetwar3869 Thanks man, I think when I wrote this comment I was under the impression that the printed sentences were from during the training and before backprop, but I realize now that first of all the backprop would've probably been done in batches, and second of all that like you said the sentences are printed after the final backprop in that epoch
I liked the explanation but unfortunately could not understand why exploding gradients is more of a problem in RNN rather than a DNN. I mean the W that gets propagated from h(t-1) to h(t) can also be in such a way that when one W is >1 the next could be
is "cell" equal to neuron? it seems to be like the case. But at 8:45, when you say that each sequence element goes through a cell each, then i am confused, is the cell really modelling the entire model?
Got a specific question: I am currently trying to classify motion in a 3d-animation. So basically I get a bunch of 3d-vectors that i am trying to get in relation over time. More specifically I want to check if the movement of the bones and joints are too fast. So my thought was to use lstm to check that. I would use the 3d-vectors for each frame as an input in a lstm-cell. Yet i am not quite sure how to set each cell, each frame in relation to the next one. Any tipps? :D
@@soareverix well it was a topic for a possible master thesis for myself, i thought a bit about it, but changed the topic due to some otver hardware related problems. However, i had an idea on how to enter all necessary information into the lstm that could work. But im currently still working, so maybe ill write back later with the idea. In my case it wasnt vr but motion capturing of movements
How can we predict the market using math? I believe it's possible through Fourier series and a few other views. Please help 🆘 I just don't understand how to get the wave form of the market and then calculate a point in time to predict the price. Itself sounds simple but idk what to
Hmm. The stock market is very hard to predict. It depends on factors that go beyond historical trends. It's a fun toy problem, but not super realistic to model. I have a video of me attempting to build a model for this too. It's one of my more recent videos
You are doing good jobs! But I do not really understand that in this case, your chars value are unique characters, so why after converting into text, it is not unique ones, words in alphabet instead?
Hi! I have some sequences generated from some initial conditions, what model should I use to have a sequence generated from some initial condition based on the data I have? seq2seq models usually predict the following data of a series but don't generate sequence from initial conditions.
hi sir, can you please send me this project code if u have"Developing an Efficient Deep Learning-Based Trusted Model for Pervasive Computing Using an LSTM-Based Classification Model"
The symbol is an epsilon which means "belongs to". So x(i) belongs to a set of vectors of real numbers with D dimensions. Simply put, x(i) is a vector of real numbers with D dimensions.









For details and code on building a translator using a transformer neural network, check out my playlist "Transformers from scratch": ruclips.net/video/QCJQG4DuHT0/видео.html
I learnt about LSTMs from so many sources; but no one explained it this well. This is some amazing content you are creating. It should be preserved.
Thank you:)
The first time that i see how someone "unrolled" the lstm network and actually demonstrated it. This could not do any professor that i saw. They only showed the picture of cells anybody could find on the internet. Thank you very much, good job!
Programmed my first LSTM with that video. Really good introduction to this topic. Right amount of math, architecture, background (GRU, RNN etc) and coding.
WTF did i just watched....man in 15 min video you explained so many topics and smoothly.....I'm new to AI but what you did was impressive. You explainaid the meaning of everything while simplifieng math concepts BUT STILL putting them in....thank you for your work, I really appreciate it
I'm super glad you appreciate this style. I'm trying to make more videos like this as of later too. :)
I’m not done with watching it. But I had to leave a comment first. I think you have really cracked the way to make people understand. Not a single professor has ever taught the way you have unfortunately. I have always wanted someone whose teaching to start from ground up and just explain everything before diving into math. You even explained what os and random was that’s never seen before in cs 😂. So thank you I really enjoy your video it is great for once someone understood a student who might be watching this does not have a phd in mathematics so explaining what each variable means and what the big picture is might save them hours of being lost and confused. Keep up the great work man I really appreciate this channel now it’s a hidden gem!!!!
i study MSc computer science at HKU, but your teaching is much better than my professor. OMG
Amazing video.. I love how you have explained a number of different concepts and explained each one with due integrity
pretty in-depth view on this
I like your pacing better than Siraj, also the simplicity
Thanks a lot! I'm going for a "here is why we do things the way we do" approach. Glad that you (and many others) find it interesting.
This man is a different beast! Way better and hence shouldn't be compared to Siraj! :) Great video.
Arun Kumar the scandal showed why Siraj was so much worse at explaining than this guy.
Farenhite oof yeah
@@beingnothing34 Dude Siraj was a fraud.
Really like your conversational explanations. Great detail presented in a palatable manner.
This makes so much more sense than my lecture...
Hello, have a question: @8:50 you mentioned x(0)... x(n) as inputs. If you had a sentence "Hello World", is a vector of "Hello" be x(0) and "World" be x(1)? If so, x(0) and x(1) will require 2 LSTM cells, and will one line of "model.add(LSTM)" have two LSTM cells to process "Hello World"? How can we visualize more than one LSTM layer then?
I like the quality of your content, I'll definitely watch your other videos !
Thanks sooo much! Enjoy your stay ;)
Thank you sooo much for linking references in the description.
Thank you SO MUCH for giving some examples of each architecture. Im following multiple ML courses on uni, but everything is abstracted away behind mathematical jargon, and never gets back to basics.
Great video!!! Everything I can see and understand from the video make compelling sense for me. Thank you so much!!
You are very welcome (sorry I am so late)
Good overview! Still relevant. LSTM's have come a long way, important for the dev of LLM that are showing SOTA performance on NLP as of this date no?
Your explanation is amazing. Love the way you joking and that makes the video more interesting❤️
Had a mighty laugh on the Sepp Hochreiter joke, thanks!
Such a great video, you explain everything so clearly and at a good pace, liked and subscribed!
Can't understand some points. If I have a set of temperature values or closing price of a day. Just one linear sequence. I need to forecast 3 future days values by 10 previous days values. So the question is which of values I need to put into the first LSTM cell, which values into the second cell and so on? The second question is how much LSTM cells I need for this calculations; does an LSTM cells count depend on previous days count or future days count?
Hi! just a question, does lstm predict on sequences of FEATURES in ONE SAMPLE or sequences of SAMPLES (outputs) in ONE BATCH? For eg. I need to predict next number as many to one. I fit first sample as x1=1, x2=2 and output y=3, next sample x1=4, x2=5 y=6. NOW Does the model look on sequence of features (x1,x2) or sequence of samples (y, which are output of the model)
Can you explain further what the hidden size argument is for in the LSTM? Many say it is the dimensionality of the output but I don't get it. The sample explanations of LSTM I saw only has 1 dimensionality so what does it mean when hidden size or number of units as some refer to is more than 1?
Don't BatchNorms and He Initilaization fix Vanishing/Exploding Gradients? ResNet actually fixed model degredation, where deeper models perform worse than smaller models. Deeper networks should learn identity connections if an optimal model has smaller models. The ResNet shortcut connection allows easy learning of mappings similar to identity mappings.
How does affect LSTMs? Why can't we just include BatchNorms to fix vanishing/exploding gradients?
Excelent video, dude! It's awesome when someone embraces both theoretical *and* practical parts. Thanks a lot
Thanks for the compliments!
Thank you very much. Why the gradient explode as a function of t/d please at 7:19?
Mind-blowing Video!. Thanks for making it.
Anytime :)
Hello! Your Link to your coursera videos is seemingly broken/expired. Can I find videos from you on coursera and can you recommend more learning material like courses and books to me?
Thank you!
Great videos.
Great video. Is it possible that the graphic at 9:45 is mislabeled? h_t is coming out at the top right where I though o_t should be emerging.
Hi , i need some help here
why we decide to make the next hidden state = the long memory after filter it ? why not the next hidden layer not = the long memory (Ct)
wow, your explanation is so simplistic!
Gosh can't wait for that video on GRU that's coming pretty soon! Besides the joke, Thanks for the video!
Thanks for watching!
Hi Siraj, could you explain why we use a dense layer ?
Max length of the sentence is 40, but why set LSTM units to 128? What is the output size of LSTM?
You are very good. Someday, you will be a great professor.
is it not better to use word embeddings rather than character vectors
Very good and informative video, shame about how many adverts though.
Do you have any videos about using RNN model for cyber threat attacks, or any source to look for study it
You cut the text into semi-redundant sequences of maxlen characters, but how does the model or performance change if you change the value of maxlen?
Thank you for this. What are U, V, and W at 8:44?
nice and concise.. good work buddy
Isn't 128 is too many for hidden size? I building an LSTM network, my input shape is [300, 5] and using hidden_size=128 results in gradient vanishing.
Also, what happens if I add more layers to the dense net which comes after LSTM? Will this architecture be able to learn? Because LSTM "requires" a relatively large learning rate, which is often too large for typical FC network I am guessing that this will cause some crazy instability as a whole. I hope you could help me with these annoying questions :). Thanks a lot for sharing your knowledge!
Sir can you do a video of Rnn example by giving numerical values
Hi, Why we use Tanh in RNN consider it is a bad activation function? Can we use ReLu?
I really liked this clear exlpanation.
This is phenomenal....great explanation dude..... ❤️
I'm confused about the part where he says "Gradient will now explode/vanish as a function of tau/d" 7:06
Can someone explain this to me?
If I got the right understanding, since the propagation of weigth should happen throught jumps over d units instead of directly to next one, the explosion problem should happen in a "smoother rate"
@@dfnoshamps Thanks for the reply, what I don't get is why it should happen at a smoother rate if you just add a skip connection?
Great!!!!!!!!!!!!!!!!!!!!!!! Lecture damm good explanation..
awesome explanation. thank you
Thanks ! Simply the best.
I'm new to AI so this might be a silly question but I thought the weights were randomly initialized, how is it possible it performed so well on the first epoch? I assumed the characters would be completely random but they make at least some semblance of words already, or is there already some learning done before the end of the first epoch?
Btw thanks so much for the video! Way clearer than others I've watched
The prediction sentence is printed after the epoch...so yes it did learn 'something' in that epoch that's why it makes a little sense
@@siddheshbalshetwar3869 Thanks man, I think when I wrote this comment I was under the impression that the printed sentences were from during the training and before backprop, but I realize now that first of all the backprop would've probably been done in batches, and second of all that like you said the sentences are printed after the final backprop in that epoch
@@ObviouslyASMR yeah any time man
The weights are randomized, the goal of a Neural Network is to make a bad guess and turn it into a better one.
OMG definitely didn't expect to see my favorite ASMR channel here lol
how to use ctc loos function for training of variable length sequences??? can you help to me??
Great video! My only complain is that I cannot find your video explaining GRUs like you said you would =p
Yea I did not do that and got caught up with some other videos later on :) My bad
I liked the explanation but unfortunately could not understand why exploding gradients is more of a problem in RNN rather than a DNN. I mean the W that gets propagated from h(t-1) to h(t) can also be in such a way that when one W is >1 the next could be
In DNN Ws can be different from layer to layer, so W in layer 1 is 0. In RNN, weights get shared, so if W>1 or W
Starts at 9:00
I don’t understand it. Suddenly a pic full of math symbols pops up it’s not labeled what are inputs outputs neurons connections weights
Great video, you are really good at explaining logically
what's your source for the images throughout this video? I'd love to use them in my own work!
Hello i'm new here, i want to ask, how do we know the value of Wi, Wf, Wo, Wc? Is it randomize? Thank you, BTW nice video
is "cell" equal to neuron? it seems to be like the case.
But at 8:45, when you say that each sequence element goes through a cell each, then i am confused, is the cell really modelling the entire model?
This is a great video , thanks for making it
High Quality Content!
what are the dimensions of the weights?
bro can u make a video on implementing Convolutions and LSTMs
this was very helpful! thank you
excellent explanation. can you show me where i can get full math derivation of backward pass of lstm?
Thanks! A quick google search takes me here: arunmallya.github.io/writeups/nn/lstm/index.html#/
It seems good.
what kind of sorcery is this?
Loading Weights generates different results to when it was trained.
Got a specific question: I am currently trying to classify motion in a 3d-animation. So basically I get a bunch of 3d-vectors that i am trying to get in relation over time. More specifically I want to check if the movement of the bones and joints are too fast. So my thought was to use lstm to check that. I would use the 3d-vectors for each frame as an input in a lstm-cell. Yet i am not quite sure how to set each cell, each frame in relation to the next one. Any tipps? :D
This is a really interesting problem I'm interested in as well, for VR purposes! Did you ever solve it?
@@soareverix well it was a topic for a possible master thesis for myself, i thought a bit about it, but changed the topic due to some otver hardware related problems. However, i had an idea on how to enter all necessary information into the lstm that could work. But im currently still working, so maybe ill write back later with the idea. In my case it wasnt vr but motion capturing of movements
How can we predict the market using math? I believe it's possible through Fourier series and a few other views. Please help 🆘 I just don't understand how to get the wave form of the market and then calculate a point in time to predict the price. Itself sounds simple but idk what to
Hmm. The stock market is very hard to predict. It depends on factors that go beyond historical trends. It's a fun toy problem, but not super realistic to model. I have a video of me attempting to build a model for this too. It's one of my more recent videos
Good video, thank you.
Great video! Thank you
keep doing the good stuff man.
Thanks dude. I'm always about that good stuff.
Best part 6:32
the presentation is at its best. What software are u using?
Thanks for the compliments Karthik. I use Camtasia Studio for editing my videos
The way he pronounced "Sepp Hocrieter" blew my brains 😅
its actually Hochreiter :)
bro you are fire, i was struggling in my deep learning course and this LTSM video really helped
good videos, but i have some questions please
Excellent lecture! Many Thanks!
Thanks for watching!
You are doing good jobs! But I do not really understand that in this case, your chars value are unique characters, so why after converting into text, it is not unique ones, words in alphabet instead?
6:37 Lmao the comedic timing, I died.
I love your videos, please make more!
equations for GRU's are wrong, it will have Ht-1 not Ht
Thank you for the great video!
Good explanation. Can u do one video on Xception model?Plz
Thanks! I have already done an Xception explanation. Check out my video on "Depthwise Separable Convolution - explained"
Hi, I have one question regarding BiLSTM neural network. Should i ask here or on your Quora profile? Thanks
Wherever you want :)
Really Awesome stuff
hi, your video was nice and i request you to make video on LSTM for speech recognization please.
Hi! I have some sequences generated from some initial conditions, what model should I use to have a sequence generated from some initial condition based on the data I have?
seq2seq models usually predict the following data of a series but don't generate sequence from initial conditions.
You should probably try open AI GPT-2....it will generate sentences for u given an initial context (or even a single word).
hi sir, can you please send me this project code if u have"Developing an Efficient Deep Learning-Based Trusted Model for Pervasive Computing Using an LSTM-Based Classification Model"
How can I get this code
At 5:24 what is that e looking symbol called?
The symbol is an epsilon which means "belongs to". So x(i) belongs to a set of vectors of real numbers with D dimensions. Simply put, x(i) is a vector of real numbers with D dimensions.
@@CodeEmporium thank you
Brother i won't understand many things how to do good and learn more advance concept
Good video!
Much appreciated
yeah we have no question marks in german 3:32
Amazing video, thanks!
Thanks for watching!
thank you so much !
thanks
Andrew NG style
your videos are funny when you're german like me