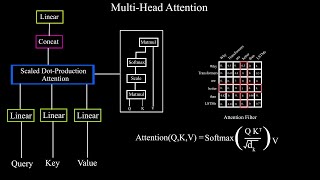
Thanks lelin, I’m glad you found the video useful. Yes, scaled dot product is a specific formulation of multiplicative attention mechanism that calculates attention weights using dot-product of query and key vectors followed by proper scaling to prevent the dot-product from growing too large.
well explained . i jhave few questions 1 : why we need Three matrix Q K V , 2 : as we know dot product finds the vector similarity that we calculate using Q and K why again need V again what role V play besides giving us back the input matrix shape .
Thanks for the great question! Each of these matrices play a different role that makes attention mechanism so powerful. We can think of the query as what the model is currently looking at, and the keys as all other aspects in the aspects. So the dot product q and k determines the relevance of what the model is looking at currently with everything else. Once the relevance of different parts of the input is established, the values are the actual content that we want to aggregate to form the output of the attention mechanism. The values hold the information that is being attended to.
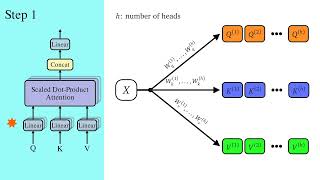
Sure, d or d_model refers to the size of the hidden units in each layer. So that’s the size of each embedding vector , as well as the input and output of each layer . The size of query key and values are d/h because multihead attention splits the input of size d by the number of heads.
your seires on transformers is really useful thank you for the content. do you refer to any documentation or have a site from where i can look at such figures and plots that you show?
Thank you for the positive feedback on my Transformers series! I'm glad to hear that you're finding it useful. I am currently working on publishing supporting articles for these videos on my Substack page (pyml.substack.com/). There, you'll be able to download the images and view additional figures and plots that complement the videos. Stay tuned for updates!
Thanks for the suggestions. Yes, absolutely! I plan to do cover other models and architectures later on after finishing this topic. I will include models that integrate attention with RNNs.
So if we start from the very first step, we tokenize the input sequence , and then we pass this sequence of tokens to an embedded layer. So if we fast track, these embedding reach the attention block as the input so let’s call them tensor X. Now in this attention block, we have 3 learnable matrices Wq, Wk, and Wv, so we multiply each matrix with X and we get Q, K and V respectively.
Thanks, this video and some of my earlier videos are made with Python ManimCE package. But it takes so much time to prepare them , so my recent videos are made with PowerPoint
That’s a good question! Making keys and queries different helps with the modeling power. It allows the model to adaptively learn how to match different aspects of the input data (represented by the queries) against all other aspects (represented by the keys) in a more effective manner. But note that there are some models that use the same weights for queries and keys too. But having different queries and keys results in more flexibility and a more powerful model.
Thanks for the comment So T is the sequence length, and d is basically the feature dimension. So I have just assumed d=5 for visualization purposes. In the paper « Attention is all you need », d is 512 but I cannot visualize matrices of such high dimensions , so just assumed d=5 I made this visualization to track the dimensionalities of matrices through these multiplication
@@PyMLstudio Thanks a lot. Another doubt, if you can answer, please: I don't understand how Transformer assigns similarity between words in a sentence based only on these words in this specific sentence. When calculating the attention weights, I believe that only based on the words of the sentence is not enough for him to measure the similarity between the words. Shouldn't there be "prior knowledge"?
@@fabriciosales3299 Absolutely, I am happy to answer any questions you may have. So, Transformer is typically pre-trained as a language model in a self-supervised manner (which we can consider as an unsupervised learning) . Besides that, no prior-knowledge for similarity of words is provided for this pre-training. During this pre-training, the Transformer will learn to predict the next word in a sequence (Causal LM) or predict a masked word (Masked LM). So, the similarities are learned through this pre-training to be able to predict the next word or the masked word. So, in summary, no other prior-knowledge is needed for the similarity of the words, and this is the job of the attention mechanism to learn which words to attend during the training of the Transformer. I hope this answers your question. Note that I am working on a new video to describe the full architecture of the Transformer and put everything together. I will publish the new video in a few days.
Thank you for your question - it’s indeed a great question. So X represents the input to a given layer, much like inputs in traditional neural networks. Specifically, in the first layer of a transformer, X is derived by calculating both the token embedding and the position embedding. For subsequent layers within the transformer, X is simply the output of the preceding layer.








Very nice video. Thank you!
Thanks 🙏🏻
thank you for detailing every matrix size in input and output, its so helpful
Cool, glad that was helpful, thanks for the comment
thank you for making it so easy to grasp the mathematical concepts!
Glad you found the videos useful
way to go, really nice summary
Wow.. So nice.
Great, very useful 👍
Great video, getting more clear 👍
The best video ever
This is explained very well😄 Thank you so much. One doubt: Is Scaled Dot-Product attention same as Multiplicative Attention?
Thanks lelin, I’m glad you found the video useful.
Yes, scaled dot product is a specific formulation of multiplicative attention mechanism that calculates attention weights using dot-product of query and key vectors followed by proper scaling to prevent the dot-product from growing too large.
well explained . i jhave few questions
1 : why we need Three matrix Q K V ,
2 : as we know dot product finds the vector similarity that we calculate using Q and K why again need V again what role V play besides giving us back the input matrix shape .
Thanks for the great question! Each of these matrices play a different role that makes attention mechanism so powerful.
We can think of the query as what the model is currently looking at, and the keys as all other aspects in the aspects. So the dot product q and k determines the relevance of what the model is looking at currently with everything else.
Once the relevance of different parts of the input is established, the values are the actual content that we want to aggregate to form the output of the attention mechanism. The values hold the information that is being attended to.
Nice explanation bro
Thank you, vary useful
You are welcome, I’m glad you found it useful! I am working on a new video for Multihead Attention, which I will post that very soon
Thanks. Can you please explain the dimensionality "d" means?
Sure, d or d_model refers to the size of the hidden units in each layer. So that’s the size of each embedding vector , as well as the input and output of each layer . The size of query key and values are d/h because multihead attention splits the input of size d by the number of heads.
your seires on transformers is really useful thank you for the content. do you refer to any documentation or have a site from where i can look at such figures and plots that you show?
Thank you for the positive feedback on my Transformers series! I'm glad to hear that you're finding it useful. I am currently working on publishing supporting articles for these videos on my Substack page (pyml.substack.com/). There, you'll be able to download the images and view additional figures and plots that complement the videos. Stay tuned for updates!
Could you also explain how attention work with RNNs?
Thanks for the suggestions. Yes, absolutely!
I plan to do cover other models and architectures later on after finishing this topic. I will include models that integrate attention with RNNs.
How to get matrix Q, K, and V?
So if we start from the very first step, we tokenize the input sequence , and then we pass this sequence of tokens to an embedded layer. So if we fast track, these embedding reach the attention block as the input so let’s call them tensor X.
Now in this attention block, we have 3 learnable matrices Wq, Wk, and Wv, so we multiply each matrix with X and we get Q, K and V respectively.
How do you make such good Model Diagrams?
Thanks, this video and some of my earlier videos are made with Python ManimCE package. But it takes so much time to prepare them , so my recent videos are made with PowerPoint
Why is the key matrix different from the query matrix?
That’s a good question! Making keys and queries different helps with the modeling power. It allows the model to adaptively learn how to match different aspects of the input data (represented by the queries) against all other aspects (represented by the keys) in a more effective manner. But note that there are some models that use the same weights for queries and keys too. But having different queries and keys results in more flexibility and a more powerful model.
❤
Thanks and congratulations by video. One doubt: why the size of D (15:28) is 5 ?
Thanks for the comment
So T is the sequence length, and d is basically the feature dimension. So I have just assumed d=5 for visualization purposes. In the paper « Attention is all you need », d is 512 but I cannot visualize matrices of such high dimensions , so just assumed d=5
I made this visualization to track the dimensionalities of matrices through these multiplication
@@PyMLstudio Thanks a lot. Another doubt, if you can answer, please: I don't understand how Transformer assigns similarity between words in a sentence based only on these words in this specific sentence. When calculating the attention weights, I believe that only based on the words of the sentence is not enough for him to measure the similarity between the words. Shouldn't there be "prior knowledge"?
@@fabriciosales3299 Absolutely, I am happy to answer any questions you may have.
So, Transformer is typically pre-trained as a language model in a self-supervised manner (which we can consider as an unsupervised learning) . Besides that, no prior-knowledge for similarity of words is provided for this pre-training. During this pre-training, the Transformer will learn to predict the next word in a sequence (Causal LM) or predict a masked word (Masked LM). So, the similarities are learned through this pre-training to be able to predict the next word or the masked word.
So, in summary, no other prior-knowledge is needed for the similarity of the words, and this is the job of the attention mechanism to learn which words to attend during the training of the Transformer.
I hope this answers your question. Note that I am working on a new video to describe the full architecture of the Transformer and put everything together. I will publish the new video in a few days.
But how to get the actual matrix for x?
Thank you for your question - it’s indeed a great question. So X represents the input to a given layer, much like inputs in traditional neural networks. Specifically, in the first layer of a transformer, X is derived by calculating both the token embedding and the position embedding. For subsequent layers within the transformer, X is simply the output of the preceding layer.
Jones Michelle Thompson Laura Jones Paul